
Intelligence artificielle
Cette section permet de configurer les options pour les fonctionnalités utilisant l'intelligence artificielle : l'enrichissement des données avec des données ouvertes, la génération d'une fonction de transformation, l'affichage des faits marquants et DigDash Agent.
Données ouvertes
Vous pouvez activer ici la fonctionnalité de données ouvertes:
- Cochez la case Activer la fonctionnalité de données ouvertes.
➡ La commande Enrichir avec des données ouvertes est alors disponible dans le menu contextuel des modèles de données.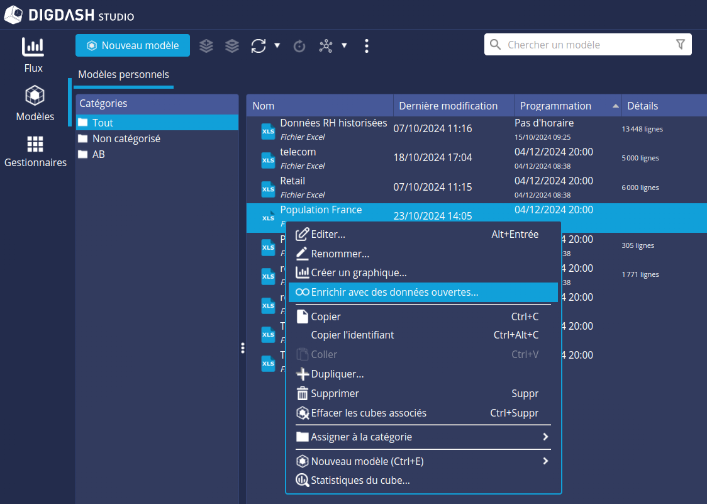
Il est également possible de détecter automatiquement si des données ouvertes compatibles avec vos données sont disponibles, à la création de votre modèle de données. Pour cela:
- Cochez la case Activer la fonctionnalité de données ouvertes à la création d'un modèle de données.
➡ Si des données ouvertes compatibles avec vos données sont disponibles, elles vous seront proposées lors de la création de votre modèle de données (après clic sur le bouton Terminer lors de la configuration du modèle de données dans le Studio).
Le champ L'identifiant du rôle contenant les modèles de données ouvertes contient l'identifiant du rôle dédié aux modèles de données ouvertes Digdash Open Data.
LLM (Grand modèle de langage)
Vous pouvez activer et spécifier ici le LLM (grand modèle de langage) utilisé pour l'assistant AI permettant la génération de fonctions de transformation.
- Cochez la case Activer le LLM.
- Sélectionnez le Fournisseur LLM dans la liste déroulante.
- Renseignez les éléments suivants :
OpenAI Google Gemini Ollama URL du serveur https://api.openai.com https://generativelanguage.googleapis.com/v1beta/models/nom_du_modèle:generateContent
L'URL contient le modèle utilisé par Gemini. Ainsi, nom_du_modèle est à remplacer par le nom du modèle choisi. Par exemple:
https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash:generateContentCliquez sur le lien suivant pour consulter la liste des modèles disponibles:
https://ai.google.dev/gemini-api/docs/models/gemini?hl=frEntrez l'URL du serveur sous la forme suivante :
http://[serveur]:[port]
Par exemple : http://lab1234.lan.digdash.com:11434Clé d'API Entrez votre clé API.
Consultez le paragraphe Configurer une clé API OpenAI si besoin.
Entrez votre clé API.
Consultez le paragraphe Configurer une clé API Gemini si besoin.
Ollama ne nécessite pas de clé API. Modèle Entrez le nom du modèle choisi.
Par exemple, gpt-3.5-turbo.Cliquez sur le lien suivant pour consulter la liste des modèles disponibles:
https://platform.openai.com/docs/modelsLe modèle n'est pas renseigné ici mais directement dans l'URL du serveur.
Le champ doit rester vide.Entrez l'identifiant du modèle.
Nous recommandons les modèles suivants :
- Codestral 22B : LLM spécialisé dans la génération de code (petit modèle performant).
Avec le niveau de quantization Q4_K_M, l'identifiant est alors codestral:22b-v0.1-q4_K_M
- Llama 3.3 70B : LLM généraliste pouvant répondre à des tâches générant du code.
Avec le niveau de quantization Q4_K_M, l'identifiant est alors llama3.3:70b-instruct-q4_K_M
Cliquez sur le lien suivant pour consulter la liste des modèles disponibles:
https://ollama.com/search - Codestral 22B : LLM spécialisé dans la génération de code (petit modèle performant).
- Cliquez sur Enregistrer.
Pour revenir aux valeurs par défaut, cliquez sur Réinitialiser.
Paramétrage des prompts
Les prompts (ou instructions) utilisés par défaut pour la génération de transformations de données sont stockés dans le répertoire /home/digdash/webapps/ddenterpriseapi/WEB-INF/classes/resources/llm. Il existe un prompt pour chaque fournisseur. ❗Ces prompts NE DOIVENT PAS être modifiés.
Vous pouvez définir un prompt personnalisé sur le même modèle en conservant les dernières lignes :
request: #/*REQUEST_CLIENT*/#
Afin d'être pris en compte, celui-ci doit se nommer custom.prompt et être placé dans le répertoire /home/digdash/appdata/default/Enterprise Server/ddenterpriseapi/config.
Faits marquants
💡 Consultez la page Afficher les faits marquants pour plus de détails sur l'utilisation des faits marquants.
Des valeurs sont paramétrées par défaut pour configurer l'affichage des faits marquants. Vous avez la possibilité de modifier ces valeurs si vous souhaitez influencer la façon dont ces faits marquants sont identifiés.
| Paramètre | Description |
|---|---|
| Nombre minimum de membres pour Mega | Nombre minimum de membres que la dimension doit contenir pour pouvoir déterminer un méga contributeur. |
| Pourcentage minimum pour Mega | Pourcentage minimum de la somme totale que doit représenter le membre pour être un méga contributeur. Par défaut, un membre doit contribuer pour au moins 40% d'une mesure donnée pour pouvoir être un méga contributeur. |
| Nombre minimum K pour TopK | Nombre minimum de membres contribuant pour au moins le "Pourcentage minimum pour TopK" à une mesure donnée (somme totale). Par défaut, 2 membres minimum doivent contribuer pour au moins 40% d'une mesure donnée pour être des top contributeurs. |
| Nombre maximum K pour TopK | Nombre maximum de membres contribuant pour au moins le "Pourcentage minimum pour TopK" à une mesure donnée (somme totale). Par défaut, 5 membres maximum doivent contribuer pour au moins 40% d'une mesure donnée pour être des top contributeurs. |
| Pourcentage K pour TopK | Pourcentage du nombre de membres permettant de déterminer K. Par défaut, K est égal à 33%. Il faut au minimum 6 membres pour obtenir un Top2. |
| Pourcentage minimum pour TopK | Pourcentage minimum d'une mesure donnée auquel les K meilleurs membres doivent contribuer pour être des Top contributeurs. Par défaut, les K meilleurs membres doivent contribuer pour au moins 40% à une mesure donnée (somme totale) pour être des top contributeurs. |
| Limite inférieure la plus basse pour la corrélation | Coefficient de corrélation minimal dans le cas d'une dimension avec 10 membres pour que la corrélation soit prise en compte. Par défaut, le coefficient de corrélation minimal est de 0,7. |
| Limite inférieure la plus haute pour la corrélation | Coefficient de corrélation minimal dans le cas d'une dimension avec 50 membres ou plus pour que la corrélation soit prise en compte. Par défaut, le coefficient de corrélation minimal est de 0,3. |
| Limite pour la corrélation | Limite du coefficient de corrélation au delà duquel la relation n'est plus considérée comme une corrélation. |
Agent
Cette section permet configurer les paramètres serveur pour l'utilisation de DigDash Agent.
Cochez Activer la fonction Agent afin d'activer un ordonnanceur qui intègre périodiquement de nouveaux cubes et stocke les vectorisations dans la base Chroma. Une fois l'option activée, les paramètres suivants sont effectifs.
| Paramètre | Description |
|---|---|
| Fréquence en secondes de la vectorisation des cubes dans la base de vecteurs | Définit la fréquence d’exécution de l'ordonnanceur. Ajustez selon la fréquence de reconstruction des cubes. La valeur minimale est de 1 seconde. Il est recommandé d'utiliser une valeur de 60 secondes. |
| URL de base du modèle de vectorisation | L’Agent prend actuellement en charge uniquement les modèles d’OVH. Nous recommandons le modèle BGE-M3 : https://bge-m3.endpoints.kepler.ai.cloud.ovh.net. |
| Clé API du modèle de vectorisation | Vous pouvez réutiliser la clé API utilisée pour le LLM. |
| URL de base du stockage des vecteurs | Définissez l’URL de base vers la base de données ChromaDB : http://localhost:8000. |
| Clé d'environnement spécifique (prod, test ou dev) | Ce paramètre optionnel définit le "tenant" (locataire) au sein de ChromaDB. Il s'agit du niveau de regroupement logique le plus élevé, permettant d'isoler totalement les bases de données et leurs collections par environnement (par exemple : prod, test, dev). |
| Délai d'expiration du stockage des vecteurs | Valeur par défaut : 30 secondes. Après ce délai, la requête est réessayée plusieurs fois avant d’échouer. |
| Forcer l'initialisation du stockage des vecteurs | Cochez cette case pour effacer complètement la base pour l’environnement spécifié. |
| Liste des rôles à vectoriser | Par défaut, tous les rôles sont vectorisés. |
| Liste des modèles à vectoriser | Par défaut, tous les modèles de données sont vectorisés. |
| Liste des hiérarchies à vectoriser | Ajoutez le nom des hiérarchies temporelles que l’Agent doit interpréter. L’Agent détectera les filtres temporels dans l’entrée utilisateur et trouvera la correspondance la plus proche parmi les membres des hiérarchies spécifiées. Si le champ est vide, aucune hiérarchie ne sera prise en compte. |