Réglages avancés des paramètres système
- Réglages Tomcat
- Paramètres de performance avancés
- Service de maintenance Automatique
- Utilisation de plusieurs serveurs en mode "Cluster"
- Autres réglages avancés
- Changement du chemin des fichiers de données
- Règlages LDAP (adswrapper) : Port et dossier des données
- Paramètres avancés de l'éditeur/viewer de tableaux de bord
- Réglages de sécurité interne
- Externalisation des paramètres dans le fichier digdash.properties
- Spécifier les paramètres de journalisation (logging) log4j.properties
- Paramètres du Desktop Studio
- Dossiers de données DigDash Enterprise
Dans ce qui suit, <digdash.appdata> fait référence à l'emplacement que vous avez choisi pour la sauvegarde des données (sources, graphiques, formats, ...).
Il doit être renseigné dans le fichier digdash.properties sous le paramètre digdash.appdata ou ddenterpriseapi.AppDataPath (voir Guide d'installation Windows ou Guide d'installation Linux)
Vous pouvez aussi le visualiser dans la page "Etat du serveur" des pages d'administration de votre serveur (serveur démarré).
Ce document décrit les réglages avancés des paramètres du serveur DigDash Enterprise (DDE).
Les fichiers suivants seront modifiés :
- server.xml
- Emplacement (Tomcat global) :
<DDE Install>/apache-tomcat/conf/server.xml
- Emplacement (Tomcat global) :
- web.xml
- Emplacement (Tomcat global) :
<DDE Install>/apache-tomcat/conf/web.xml
- Emplacement (Tomcat global) :
- system.xml
- Emplacement :
<digdash.appdata>/Enterprise Server/ddenterpriseapi/config/system.xml
- Emplacement :
- digdash.properties
- Emplacement :
<DDE Install>/digdash.properties
ou /etc/digdash/digdash.properties (sous linux)
ou l'emplacement personnalisé que vous auriez configuré.
- Emplacement :
- web.xml (cette méthode est obsolète, veuillez utiliser le fichier digdash.properties)
- Emplacement (ddenterpriseapi) :
<DDE Install>/apache-tomcat/webapps/ddenterpriseapi/WEB-INF/web.xml - Emplacement (dashboard) :
<DDE Install>/apache-tomcat/webapps/digdash_dashboard/WEB-INF/web.xml - Emplacement (adminconsole) :
<DDE Install>/apache-tomcat/webapps/adminconsole/WEB-INF/web.xml - Emplacement (studio) :
<DDE Install>/apache-tomcat/webapps/studio/WEB-INF/web.xml - Emplacement (adswrapper) :
<DDE Install>/apache-tomcat/webapps/adswrapper/WEB-INF/web.xml
- Emplacement (ddenterpriseapi) :
- setenv.bat (Windows)
- Emplacement : <DDE Install>/configure/setenv.bat
- setenv.sh (Linux)
- Emplacement : <DDE Install>/apache-tomcat/bin/setenv.sh
- dashboard_system.xml
- Emplacement : <digdash.appdata>/Application Data/Enterprise Server/dashboard_system.xml
Réglages Tomcat
Allouer plus de mémoire à Tomcat
Fichier modifié : setenv.bat ou setenv.sh
Sous windows setenv.bat se trouve dans le dossier <install DD>/configure.
Sous linux setenv.sh il se trouve dans le dossier <install DD>/apache-tomcat/bin
Trouvez les lignes suivante au début du fichier :
set JVMMX=512
Changer les 2 occurrences "512" en la quantité de mémoire (méga-octets) que vous voulez allouer à Tomcat. Par exemple "4096" allouera 4 Go de mémoire à Tomcat :
set JVMMX=4096
Changer les ports réseau Tomcat
Fichier modifié : server.xml
Si un des ports nécessaires à Tomcat est déjà utilisé par un autre processus, alors il ne se lancera pas. Il est nécessaire de vérifier la disponibilité des ports et si besoin de reconfigurer Tomcat. Par défaut les 3 ports suivants sont configurés : 8005, 8080 et 8009. Pour les modifier :
- Ouvrez le répertoire <install DDE>\apache-tomcat/conf puis éditer le fichier server.xml
- Chercher et remplacer les valeurs des ports 8005, 8080 et 8009 par des numéros de port disponibles sur le système
Changer la durée de vie des sessions inactives (timeout)
Fichier modifié : web.xml (configuration globale de Tomcat situé à l'emplacement <DDE Install>/apache-tomcat/conf/web.xml)
Trouvez les lignes suivantes dans le fichier :
<session-timeout>30</session-timeout>
</session-config>
Changez la valeur pour modifier la durée de vie en minutes d'une session inactive (timeout). Par défaut le timeout est de 30 minutes.
Changer le nombre maximum de requêtes simultanées
Fichier modifié : server.xml
Par défaut Tomcat n’acceptera pas plus de 200 requêtes simultanées. Ce paramétrage peut se révéler limitant dans le cas d’un déploiement à un grand nombre d’utilisateurs (plusieurs milliers ou millions), ou lors d’un bench de performance (ex. jmeter) qui exécute des centaines ou des milliers de requêtes simultanées.
Pour augmenter cette limite, il faut ajouter un attribut maxthreads dans l’élément Connector correspondant au connecteur utilisé.
Exemple lorsque le connecteur utilisé est http (il n’y a pas d’Apache en front-end) :
Exemple lorsque le connecteur utilisé est AJP (il y a un Apache en front-end) :
Activer la compression HTTP
Fichier modifié : server.xml
La compression HTTP permet de diminuer la consommation de la bande passante du réseau en compressant les réponses HTTP. Par défaut cette option n’est pas activée dans Tomcat, même si tous les navigateurs modernes la supportent.
Cette option permet d’économiser parfois jusqu’à 90 % la bande passante sur certains types de fichiers : HTML, Javascript, CSS. En consommant peu de CPU sur le serveur et le client.
Dans le fichier server.xml ajoutez les attributs compression="on" et compressionMinSize="40000" sur le connecteur HTTP/1.1:
Exemple :
L’attribut compressionMinSize définit une taille minimale de réponse (en octets) au dessous de laquelle la compression n’est pas utilisée. Il est conseillé de spécifier cet attribut à une valeur suffisante pour ne pas compresser des fichiers déjà très petits (icônes PNG…).
Paramètres de performance avancés
Fichier modifié : system.xml
Exemple de syntaxe XML :
Threads utilisés pour l'exécution des flux programmés
Modifie le nombre de « threads » utilisés pour l'exécution des flux programmés (ordonnanceur) ou sur événement.
Paramètres disponibles :
- Nom : MAX_TP_EXECSIZE
- Valeur : entier > 0 (défaut : 16)
Description : Nombre de threads maximum de traitement des tâches de synchronisation. - Nom : TP_SYNC_PRIORITY
Valeur : chaîne ("flow" ou "none") (défaut : flow)
Description : Mode de priorité des tâches. Valeur flow : Traite la synchronisation du flux le plus tôt possible après que le cube ait été généré pour ce flux. Valeur none : le flux sera synchronisé quand il y aura de la place dans la file de threads. Ce paramètre n'est pris en compte que lorsque que le paramètre TP_PRIORITYPOOL est à true. - Nom : TP_SYNC_GROUPFLOWBYCUBE
Valeur : booléen (défaut : false)
Description : Change le mode de traitement des tâches en attente. Valeur false : les tâches de traitements des flux sont répartis sur tous les threads disponibles quel que soit le cube utilisé. Cela entraine un traitement en parallèle des flux au détriment des cubes, recommandé lorsqu'il y a peu de cubes mais beaucoup de flux. Valeur true : regroupe les traitements des flux d'un même cube sur un seul thread. Cela entraine un traitement en parallèle des cubes au détriment des flux, recommandé lorsqu'il y a beaucoup de cubes différents et peu de flux utilisant les même cubes. Ce paramètre n'est pris en compte que lorsque que le paramètre TP_PRIORITYPOOL est à true.
Threads utilisés pour l'exécution des flux interactifs
Modifie le nombre de « threads » utilisés pour l'exécution interactive des flux (Studio, tableau de bord, mobile, etc).
Paramètres disponibles :
- Nom : MAX_TP_PLAYSIZE
- Valeur : entier > 0 (défaut : 16)
Description : Nombre de threads maximum de traitement des tâches de synchronisation. - Nom : TP_PLAY_PRIORITY
Valeur : chaine ("flow" ou "none") (défaut : flow)
Description : Mode de priorité des tâches. Valeur flow : Traite la synchronisation du flux le plus tôt possible après que le cube ait été généré pour ce flux. Valeur none : le flux sera synchronisé quand il y aura de la place dans la file de threads. Ce paramètre n'est pris en compte que lorsque que le paramètre TP_PRIORITYPOOL est à true. - Nom : TP_PLAY_GROUPFLOWBYCUBE
Valeur : booléen (défaut : false)
Description : Change le mode de traitement des tâches en attente. Valeur false : les tâches de traitements des flux sont répartis sur tous les threads disponibles quel que soit le cube utilisé. Cela entraine un traitement en parallèle des flux au détriment des cubes, recommandé lorsqu'il y a peu de cubes mais beaucoup de flux. Valeur true : regroupe les traitements des flux d'un même cube sur un seul thread. Cela entraine un traitement en parallèle des cubes au détriment des flux, recommandé lorsqu'il y a beaucoup de cubes différents et peu de flux utilisant les même cubes. Ce paramètre n'est pris en compte que lorsque que le paramètre TP_PRIORITYPOOL est à true.
Délais de suppression des cubes en mémoire
Modifie la manière dont le Cube Manager supprime les cubes inutilisés en mémoire.
Les paramètres suivants modifient la manière dont les cubes non utilisés depuis un certain temps sont supprimés, même si la session est toujours active.
Paramètres disponibles :
- Nom : CUBE_TIMEOUT_INTERACTIVE
Valeur : minutes > 0 (défaut : 10 minutes)
Description : Durée de la période d'inactivité pour un cube chargé en mode interactif (navigation du cube sur le serveur) - Nom : CUBE_TIMEOUT_SYNC
Valeur : minutes > 0 (défaut : 4 minutes)
Description : Durée de la période d'inactivité pour un cube chargé en mode programmé (génération d'un flux programmé) - Nom : CUBE_TIMEOUT_PERIOD
Valeur : minutes > 0 (défaut : 2 minutes)
Description : Intervalle de vérification de l'inactivité des cubes, devrait être au moins CUBE_TIMEOUT_SYNC / 2
Performance des cubes de données
Ces paramètres affecteront le traitement interactif des cubes de données (aplatissement en cubes résultats pendant l'affichage). Ces paramètres n'affectent pas la génération des cubes de données.
Paramètres disponibles :
- Nom : CUBEPART_MAXSIZEMB
Valeur : méga-octets > 0 (défaut : 100 Mo)
Description : Taille d'une part de cube en méga-octets. Une part de cube est une partie du cube de données qui peut être traitée (aplatie) en parallèle ou distribuée sur d'autres serveur DigDash Enterprise en mode cluster (voir chapitre "Utilisation de plusieurs serveurs en mode cluster" dans ce document). - Nom : TP_MCUBESIZE
Valeur : threads > 0 (défaut : 64 threads)
Description : Taille de la file de threads utilisés pour le traitement en parallèle des parts de cube. Les gros cubes (ex: plusieurs millions/milliards de lignes) sont traités en parallèle par le serveur, et/ou par d'autres serveurs (en mode cluster). Ce paramètre est le nombre d'unités parallèle de traitement (thread) sur une machine. Chaque part de cube occupe une unité de la file le temps de son traitement, si la file est pleine les unités supplémentaires sont mises en attente. - Nom : MCUBE_ROWS_PER_THREAD
Valeur : lignes > 0 (défaut : 100000)
Description : C'est la limite du nombre de ligne d'un cube de données au delà de laquelle le serveur DigDash Enterprise activera le traitement parallèle des parts du cube (s'il y a plus d'une part pour ce cube). En dessous de cette limite, le traitement du cube n'est pas parallélisé mais séquentiel.
Autres paramètres de performance
Les paramètres suivants servent à analyser ou optimiser les performances du système.
Paramètres disponibles :
- Nom : LOW_MEMORY_THRESHOLD
Valeur : pourcentage > 0 (défaut : 10%)
Description : C’est le seuil en pourcentage de mémoire libre restante au dessous duquel le système émettra une alerte de mémoire basse. Cette alerte est visible dans la page d’état du serveur pendant 24 heures. Elle est aussi enregistrée dans la base de données DDAudit si le service d’audit système est démarré.
Enfin, un événement DigDash est aussi déclenché lorsque le seuil est atteint : SYSCHECK_LOWMEM. Un exemple d’utilisation de cet événement est donné dans le document de déploiement du module DDAudit. - Nom : TP_PRIORITYPOOL
Valeur : booléen (défaut : true)
Description : Utilise un pool de threads de rafraîchissements avec gestion de priorité pour les rafraîchissements de flux et cubes. Voir paramètres TP_PLAY_GROUPFLOWBYCUBE, TP_SYNC_GROUPFLOWBYCUBE, TP_PLAY_GROUPFLOWBYCUBE, TP_SYNC_GROUPFLOWBYCUBE - Nom : PROP_JS_OPTIM_LEVEL
Valeur : niveau d'optimisation de -1 à 9 (défaut : 1)
Description : Permet de définir le niveau d'optimisation utilisé lors de la compilation de javascript. -1 désactive la compilation, 0 désactive seulement l'optimisation. Le niveau maximal d'optimisation est 9, cependant il est possible que l'optimisation provoque des erreurs lors de la compilation.
Service de maintenance Automatique
DigDash Enterprise fournit un service de maintenance composé :
- D’un nettoyeur de fichiers (connu aussi en tant que Files GC) nettoyant l'ensemble des fichiers inutilisés : vieux fichiers de l'historique, cubes et autres fichiers dépendant des flux.
- D’une sauvegarde automatique de la configuration
Nettoyeur de fichiers
Le nettoyeur nettoie les fichiers non utilisés par les portefeuilles des utilisateurs et des rôles.
Le nettoyage parcourt les index de tous les utilisateurs, ainsi que le disque, afin de trouver les fichiers qui ne sont plus liés aux index. Les fichiers identifiés sont supprimés. Les fichiers effacés sont les suivants : fichiers de cubes (.dcg), fichiers js des cubes (cube_data_id.js), modèles (cube_dm_id.js) et flux (cube_view_id_js).
Cette opération présente l'avantage de libérer de l'espace disque et potentiellement d'accélérer les recherches de fichiers js, qui peuvent devenir non négligeables sur des volumétries importantes (nombre de cubes personnels * nb historiques > 100000)
Selon l'âge du serveur et la volumétrie des fichiers concernés (nombre de rafraîchissements effectués...), l'opération peut prendre beaucoup de temps lors de sa première exécution (sur certains déploiements comportant beaucoup d'utilisateurs et beaucoup de cubes personnalisés, une à deux heures).
Ensuite, si le nettoyage est fait de manière régulière, le temps d'exécution sera moins long. Ce temps dépend énormément de la performance du système de fichiers et de la machine, ce qui le rend difficilement estimable.
Sauvegarde automatique
La sauvegarde automatique est effectuée avant le nettoyage des fichiers. Le fichier généré est copié dans le dossier de configuration <digdash.appdata>/Enterprise Server/<domaine>/backups/<date du jour>.zip
Par défaut, la maintenance se fait tous les jours à minuit.
Activation, désactivation et/ou nettoyage au démarrage
Ce paragraphe décrit comment activer et programmer le service de maintenance.
L'activation du nettoyeur de fichiers peut se faire de deux manières :
1- Depuis la page état du serveur :
La page Etat du serveur est accessible depuis la page d'accueil de DigDash Enterprise puis en cliquant successivement sur les liens Configuration et Etat du serveur.
Dans la rubrique Etat du nettoyeur de fichiers, cliquez sur la flèche verte figurant à côté de Nettoyeur de fichier démarré pour démarrer le nettoyeur :
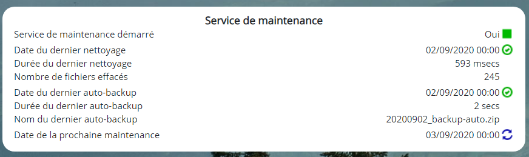
Le prochain nettoyage aura lieu à minuit. Pour démarrer le nettoyeur de fichiers immédiatement, cliquez sur l’icône  .
.
2- Depuis le fichier digdash.properties :
Fichier modifié : digdash.properties
Voir le chapitre "Externalisation des paramètres dans un fichier properties" pour effectuer cette manipulation.
Active ou non le module Files GC et/ou lance le nettoyage au démarrage du serveur.
Paramètres disponibles :
- Nom : ddenterpriseapi.startCleaner
Valeur : booléen (défaut : false)
Description :- true : nettoyage automatique des fichiers programmé.
Note: l'heure du nettoyage est définie dans system.xml, par le paramètre FILESGC_SCHEDXML.
L'heure de nettoyage par défaut (si aucune n'est spécifiée dans system.xml, FILESGC_SCHEDXML) est tous les jours à 0:00 - false (défaut) : pas d'utilisation du nettoyeur de fichiers
- true : nettoyage automatique des fichiers programmé.
- Nom : ddenterpriseapi.cleanOnStart
Valeur : booléen (défaut : false)
Description :- true : nettoie les fichiers inutilisés au démarrage du serveur (fichiers de l'historique, cubes, fichiers résultats,...)
- false (défaut) : ne nettoie pas les fichiers inutilisés au démarrage du serveur
- Nom : ddenterpriseapi.autoBackup
Valeur : booléen (défaut : false)
Description :- *. true : active la sauvegarde automatique programmée
- false (défaut) : n’active pas la sauvegarde automatique programmée
Programmation et options de la maintenance automatique
Fichier modifié : system.xml.
Paramètres disponibles :
- Nom : FILESGC_SCHEDXML
Valeur : phrase XML (encodée) (défaut : aucune)
Description : Ce paramètre contient une phrase XML encodée décrivant la fréquence de programmation.
Exemple :
value="<Schedule frequency="daily"
fromDay="11" fromHour="0"
fromMinute="0" fromMonth="7"
fromYear="2011" periods="1"
time="0:0"/>"></Property>
Les attributs intéressants sont : frequency (hourly, daily ou monthly), periods (nombre d'heures, jours ou mois entre 2 nettoyages) et time (heure du nettoyage pour les fréquences daily et monthly). Cet exemple signifie tous les jours (frequency="daily" et periods="1") à 0:00 (time="0:0").
- Nom : FILESGC_SESSIONSCHECK
Valeur : true/false (booléen) (défaut : aucune, équivaut à true)
Description : Ce paramètre indique si le nettoyeur de fichiers doit vérifier les sessions actives avant de se lancer (true), ou s'il se lance qu'elle que soit l'état des sessions actives (false). Dans ce dernier cas, toutes les sessions seront déconnectées instantanément.
Exemple :
- Nom : USEAUTOBACKUP
Valeur : true/false (booléen) (défaut : aucune, équivaut à false)
Description : Ce paramètre indique si le service de maintenance effectue aussi une sauvegarde complète de la configuration avant d’exécuter le nettoyage des fichiers.
Utilisation de plusieurs serveurs en mode "Cluster"
Pour gérer un plus grand volume de données (milliard de lignes), il est possible d'utiliser plusieurs serveurs en mode "Cluster". Chaque serveur devient un nœud de calcul du cluster.
Ce dernier regroupe un serveur maître et des serveurs esclaves.
Le serveur maître s'occupe de gérer les modèles, les documents, les rôles, les utilisateurs, les sessions et de générer les cubes et les flux (rafraîchissement). A l'identique d'un serveur Digdash Enterprise en mode standard mono-machine.
Les serveurs esclaves additionnels ne sont utilisés que pour aider à l’aplatissement interactif des cubes de données volumineux, lors de l'affichage de flux, filtrage, drills, etc.
Il existe deux architectures de clustering dans DigDash Enterprise :
- Clustering interne : Décrit dans ce chapitre
- Cluster Apache Ignite : Module Cluster Apache Ignite
Installer DigDash Enterprise en mode "Cluster"
Pré-requis: plusieurs machines connectées entre elles par le réseau
Serveur maître (sur la machine la plus puissante du cluster)
- Installation standard de DigDash Enterprise (voir ).
- Démarrer le serveur normalement avec start_servers.bat
Serveur esclave (sur chacune des autres machines du cluster)
- Installation standard de DigDash Enterprise (voir Guide d'installation Windows ou Guide d'installation Linux).
La différence est qu'un serveur esclave n'a pas besoin de licence pour servir d'unité de calcul au cluster, ni d'annuaire LDAP, ni de l'application digdash_dasboard dont le war peut être supprimé de Tomcat. - Démarrer uniquement le module Tomcat, avec start_tomcat.bat ou apache_tomcat/bin/startup.sh
Configurer le cluster
Procédure à répéter sur chaque serveur du cluster
- Avec un navigateur, se connecter à la page principale de DigDash Enterprise (ex: http://<serveur>:8080)
- Cliquer sur Configuration, puis Paramètres Serveur
- S'identifier en tant qu'administrateur de DigDash Enterprise (admin/admin par défaut) pour afficher la page des paramètres du serveur
- Cliquer en bas de page sur le lien Paramètres du cluster
- Remplir les différents champs en fonction de chaque machine serveur (voir explications ci-dessous)
Section Performance du système

La section Performance du système définit les capacités de la machine courante dans le cluster. Les paramètres Nombre de CPU, Score CPU et Mémoire allouée permettent de répartir au mieux la charge de calcul.
- Nombres de CPU : le nombre de processeurs * nombre de cœurs sur chaque processeurs. Potentiellement multiplié par un facteur si les processeurs bénéficient d'une technologie type Hyper-threading. Par défaut -1, s'appuie sur les données renvoyées par le système d'exploitation
- Score CPU : c'est une note entre 1 et 10 qui permet de relativiser la performance d'un noeud du cluster par rapport aux autres (cas d'un cluster hétérogène). Par défaut -1 donne une note moyenne (5).
- Mémoire allouée : la fraction de la mémoire maximale autorisée dans le cadre d'utilisation du serveur comme unité de calcul. Cette valeur est inférieure ou égale à la mémoire allouée au serveur Tomcat. Par défaut -1 autorise toute la mémoire.
Section Clusters autorisés
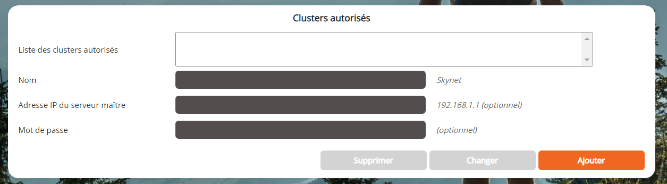
La section Clusters autorisés permet de spécifier si la machine courante peut être utilisée comme esclave d'un ou plusieurs cluster(s), et si oui lesquels. En effet une machine peut servir à plusieurs clusters DigDash Enterprise. Cette section restreint cette utilisation en tant qu'esclave à seulement certains clusters (liste Sélection) ,
C'est également dans cette section que nous définissons le Mot de passe du serveur courante dans le cluster sélectionné. Sans mot de passe le serveur ne peut être esclave dans ce cluster.
Pour ajouter un cluster autorisé à utiliser ce serveur esclave:
- Nom : nom du cluster (arbitraire)
- Adresse IP du serveur maître : adresse IP du serveur maître du cluster autorisé à utiliser ce serveur comme esclave (ex: http://192.168.1.1)
- Mot de passe : Mot de passe de l'esclave dans le contexte du cluster sélectionné
- Cliquer sur le bouton Ajouter pour ajouter ce cluster à la liste des clusters autorisés
Section Définition du cluster
A renseigner seulement sur le serveur Maître du cluster
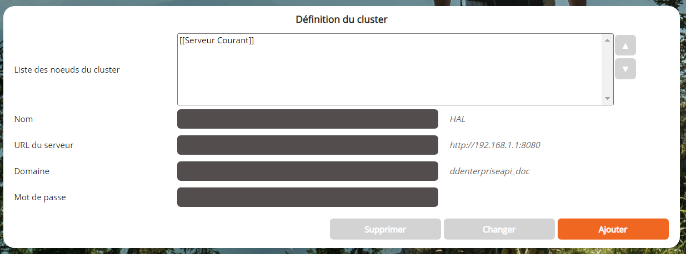
La section Définition du cluster ne concerne que le serveur maître du cluster. C'est ici que nous créons un cluster en listant les serveurs esclaves du cluster ainsi que le maître lui-même (liste Sélection, champs Nom, Adresse, Domaine et Mot de passe). Le serveur maître est implicitement le serveur via lequel vous vous êtes connecté à cette page.
Pour ajouter une machine esclave au cluster:
- Nom : nom de machine esclave (arbitraire)
- URL du serveur : URL du serveur esclave (ex: http://192.168.1.123:8080)
- Domaine : Domaine DigDash Enterprise (par défaut ddenterpriseapi)
- Mot de passe : Mot de passe de l'esclave tel que vous l'avez précédemment tapé lors de la configuration de la machine esclave (section Clusters autorisés, champ Mot de passe)
- Cliquer sur le bouton Ajouter pour ajouter cette machine à votre cluster.
Utilisation de plusieurs maîtres dans un cluster
Certain déploiements nécessitent l’utilisation de plusieurs serveurs maîtres au sein d’un même « cluster ». Par exemple dans le cas d’un load balancer HTTP en amont qui envoie les sessions utilisateurs sur l’une ou l’autre machine maître. Ce mode est supporté dans DigDash en définissant plusieurs clusters identiques (un par machine maître). La liste des machines (Section Définition du cluster) doit être strictement identique sur toutes les définitions des clusters. C’est pour cela qu’il est possible de changer l’ordre des machines dans cette liste.
Exemple : On souhaite définir un cluster qui consiste en deux machines A et B. Chacune des deux machines est maître et esclave de l’autre.
On doit définir non pas un mais deux clusters A et B :
Dans la définition du cluster A :
- Serveur courant : machine A (maître de ce cluster)
- machine B (esclave de ce cluster)
Dans la définition du cluster B :
- machine A (esclave de ce cluster)
- Serveur courant : machine B (maître de ce cluster)
On voit que dans le cluster B, le maître (B) n’est pas la première machine de la liste. Ce qui est important ici c’est que la liste machine A, machine B est bien la même sur les deux clusters (qu’elle que soit leur fonction propre au sein de leur cluster respectif).
Paramètres avancés spécifiques au clusters
Fichier modifié : system.xml
Exemple de syntaxe XML :
Paramètres disponibles :
- Nom : CUBE_UPLOAD_MODE
Valeur : entier : 0, 1 ou 2 (défaut : 1)
Description : Spécifie si les parts de cube doivent être téléchargées du serveur maître vers les serveurs esclaves au moment ou un utilisateur interagit avec le cube (1), quand le cube est généré par le serveur maître (2), ou jamais (0). Voir également le chapitre suivant : "Utiliser le cluster". - Nom : CLUSTER_TIMEOUT
Valeur : entier : (millisecondes, défaut: 30000)
Description : Spécifie le timeout de toutes les requêtes intra-cluster (entre le maître et les esclaves), à l’exception de la requête de vérification de disponibilité d’un esclave (voir ci-dessous) - Nom : CLUSTER_CHECK_TIMEOUT
Valeur : entier : (millisecondes, défaut: 5000)
Description : Spécifie le timeout de la requête de vérification de disponibilité d’un esclave. Ce timeout est plus court pour empêcher de bloquer trop longtemps le maître dans le cas ou un esclave est déconnecté du réseau.
Utiliser le cluster
Dans un déploiement simple en mode cluster il n'y a rien à faire de plus que ce qui a été écrit précédemment.
Malgré tout, il y a certains détails intéressants qui peuvent aider à améliorer la performance d'un cluster.
Le cluster est utilisé en fonction de la taille du cubes de données. En dessous d'un certain seuil, dépendant du cube, de la machine maître et des esclaves, il est possible que le cluster ne soit pas utilisé. Par contre si la taille d'un ou plusieurs cubes de données devient importante, par exemple au delà de plusieurs centaines de millions de lignes, ceux-ci seront découpés en plusieurs parties et leur calcul (aplatissement) sera réparti en parallèle sur tous les processeurs disponibles du cluster pour diminuer le temps de réponse global. Et ceci pour chaque aplatissement d'un gros cube par un utilisateur du tableau de bord, du mobile, etc.
Il est à noter que la génération des cubes est de la responsabilité du serveur maître. Les esclaves n'interviennent que lors des aplatissements interactifs de cubes déjà générés (ex: affichage d'un flux, filtrage, drill...)
Les morceaux de cubes sont envoyés aux esclaves à la demande (s'ils ne les ont pas déjà). Ceci peut induire un ralentissement du système sur un premier aplatissement demandé par un utilisateur, notamment si la bande passante du réseau est faible (< 1 gigabit).
Il y a toutefois différents moyens d'éviter cet encombrement du réseau. Voici quelques suggestions :
Un premier moyen est de disposer du dossier cubes (sous-dossier de Application Data/Enterprise Server/ddenterpriseapi par défaut) sur un disque réseau accessible à toutes les machines du cluster. Par exemple via un lien symbolique (Linux, NFS). Ce lien devra être établi pour toutes les machines du cluster. Le principe est que le serveur maître générera les cubes dans ce dossier réseau, et lors de l'interaction d'un utilisateur avec le système, maître et esclaves auront tous une vue commune des cubes. La lecture des cubes du disque n'étant faite qu'une fois dans le cycle de vie d'un cube (cube in-memory), l'impact du dossier réseau sur les performances est négligeable.
Un autre moyen, est d'utiliser un outil tierce de synchronisation automatique de dossiers entre plusieurs machines, qui pourra copier l'ensemble du dossier cubes du serveur, après leur génération, vers les machines esclaves. Le principe est que le serveur maître générera les cubes dans son dossier local, puis l'outil de synchronisation copiera ce dossier sur toutes les machines esclaves. Tout ceci en dehors des périodes d'activité du serveur. Maître et esclaves auront tous une vue identique des cubes.
Autres réglages avancés
Changement du chemin des fichiers de données
DigDash Enterprise stocke les informations de configuration, les modèles de données, les portefeuilles d'information, les cubes, l'historique des flux et d'autres fichiers de travail dans le dossier de l'utilisateur du système d'exploitation, dans un sous dossier Application Data/Enterprise Server/<domaine>.
Par exemple sous Windows, ce dossier est :
C:\Users\<utilisateur>\AppData\Roaming\Enterprise Server\ddenterpriseapi
Il est important de modifier ce dossier pour en garantir l'accessibilité (droits en lecture/écriture/exécution) et pour maitriser l'espace de stockage (ce dossier peut être volumineux).
Cette modification est aussi intéressante pour des raisons d'organisation, de scripting, etc.
Pour plus de détails rendez-vous dans les Guide d'installation Windows ou Guide d'installation Linux.
Règlages LDAP (adswrapper) : Port et dossier des données
Fichier modifié : digdash.properties
Voir le chapitre "Externalisation des paramètres dans un fichier properties" pour effectuer cette manipulation.
Le paramètre <nom du fichier war>.ads.ldap.port (valeur par défaut : 11389) défini le port réseau utilisé par le serveur LDAP intégré à DigDash Enterprise.
Il faut changer cette valeur si elle est déjà utilisée par un autre processus sur la machine, ou une autre instance LDAP (d'un autre domaine DigDash sur la même machine par exemple).
Exemple : si l'application s'appelle adswrapper (adswrapper.war) :
- adswrapper.ads.ldap.port=11590
Pour changer l'emplacement d'écriture des données de l'annuaire LDAP, voir Guide d'installation Windows ou Guide d'installation Linux.
Paramètres avancés de l'éditeur/viewer de tableaux de bord
Fichier modifié : digdash.properties
Voir le chapitre "Externalisation des paramètres dans un fichier properties" pour effectuer cette manipulation.
Paramètres disponibles :
- Nom : SERVERURL
Valeur : URL du serveur DigDash Enteprise
Description : URL du serveur sur lequel le tableau de bord doit se connecter en priorité. - Nom : DOMAIN
Valeur : Nom du domaine DigDash Enterprise
Description : Nom du domaine sur lequel le tableau de bord doit se connecter en priorité. - Nom : FORCESERVERURL
Valeur : Booléen (défaut : false)
Description : Utilisé avec le paramètre SERVERURL. Force le serveur sur lequel le tableau de bord se connecte. L'utilisateur ne peut pas choisir un autre serveur. - Nom : FORCEDOMAIN
Valeur : Booléen (défaut : false)
Description : Utilisé avec le paramètre DOMAIN. Force le domaine sur lequel le tableau de bord se connecte. L'utilisateur ne peut pas choisir un autre domaine. - Nom : GRIDSIZEEDITOR
Valeur : Entier (défaut: 10)
Description : Taille en pixel de la grille magnétique d'édition du tableau de bord. - Nom : THEME
Valeur : Nom du thème (défaut: vide)
Description : Nom du thème par défaut utilisé pour les utilisateur n'ayant pas de thème spécifique spécifié.
- Nom : urlLogout
Valeur : URL
Description : Spécifie une URL de sortie vers laquelle est redirigé l’utilisateur après une déconnexion du tableau de bord. Voir le paragraphe « Redirection lors de la déconnexion du tableau de bord ». - Nom : CANCHANGEPASSWORD
Valeur : Booléen (défault : false)
Description : Permet l’activation d’un hyperlien « Mot de passe perdu » dans la page de login du tableau de bord. Cet hyperlien envoie un code de réinitialisation par émail à l’utilisateur. Voir paragraphe « Activation de la fonctionnalité de réinitialisation du mot de passe »
Exemple de contenu partiel du fichier digdash.properties :
digdash_dashboard.FORCESERVERURL=true
digdash_dashboard.DOMAIN=ddenterpriseapi
digdash_dashboard.FORCEDOMAIN=true
digdash_dashboard.GRIDSIZEEDITOR=15
digdash_dashboard.THEME=Flat
digdash_dashboard.urlLogout=disconnected.html
digdash_dashboard.CANCHANGEPASSWORD=true
Redirection lors de la déconnexion du tableau de bord
Fichier modifié : digdash.properties (voir le chapitre précédent)
Vous pouvez spécifier une URL qui sera affichée dans le navigateur quand l'utilisateur se déconnecte du tableau de bord (bouton Déconnexion).
Modifier la valeur du paramètre urlLogout comme dans l'exemple suivant. Par défaut la valeur est vide, signifiant un retour à la page d'authentification du tableau de bord.
Les URLs relatives sont autorisées, par rapport à l'url de index.html de l'application digdash_dashboard :
Activation de la fonctionnalité de réinitialisation de mot de passe
Fichier modifié : digdash.properties, et page de Configuration des serveur DigDash
Vous pouvez activer la fonctionnalité de réinitialisation de mot de passe perdu.
Cette fonctionnalité affiche un hyperlien « Mot de passe oublié » dans la page de login du tableau de bord qui envoie à l’utilisateur un email contenant un code de réinitialisation de son mot de passe.
Ensuite l’utilisateur est redirigé vers une interface de réinitialisation pour saisir ce code et un nouveau mot de passe.
Prérequis sur le serveur DigDash :
- La fonctionnalité doit être aussi activée via la page de Configuration des serveurs / Avancé / Divers / Autoriser la réinitialisation de mot de passe
- Un serveur email valide doit être configuré dans la page Configuration des serveurs / Avancé / Serveur émail système
- Les utilisateurs doivent avoir une adresse email valide dans le champ LDAP digdashMail
L’activation de la fonction coté tableau de bord se fait en passant la variable CANCHANGEPASSWORD à la valeur true (voir le chapitre Paramètres avancés de l'éditeur/viewer de tableaux de bord).
Optionnel : Personnalisastion de l’email du code de réinitialisation
Le sujet et le corps de l’émail du code de réinitialisation peuvent être customisés de la manière suivante :
- Démarrer le Studio DigDash
- Menu Outils / Gestionnaire de traductions...
- Clic-droit sur la section GLOBAL puis Ajouter…
Nom de la clé : LostPasswordMailSubject
Saisir le sujet de l’émail dans les langues qui vous intéressent.
- Clic-droit sur la section GLOBAL puis Ajouter…
Nom de la clé : LostPasswordMailText
Saisir le corps de l’émail dans les langues qui vous intéressent. Attention le corps de l’émail doit contenir au moins le mot-clé ${code} qui sera substitué par le code de réinitialisation. Un autre mot-clé disponible est ${user}.
Nous déconseillons d’indiquer trop d’informations dans cet émail, c’est pourquoi dans le message par défaut nous n’indiquons que le code de réinitialisation.
Paramètres avancés spécifiques à la fonctionnalité de réinitialisation de mot de passe
Fichier modifié : system.xml
Exemple de syntaxe XML :
Paramètres disponibles :
- Nom : PROP_RESET_PASS_HASH
Valeur : Chaîne non vide (défaut : aléatoire)
Description : Spécifie le code sel à utiliser pour la génération du code de réinitialisation de mot de passe. Par défaut cette chaîne est aléatoire, générée au lancement du serveur. Vous pouvez spécifier une chaîne de caractère qui sera utilisée par l’algorithme de génération du code de réinitialisation. Ceci peut-être utile si vous avez plusieurs serveurs (load-balancing HTTP) et pour qu’un code généré sur un serveur soit utilisable sur un autre. - Nom : PROP_RESET_PASS_VALIDITY
Valeur : entier positif (défaut : 1)
Description : Spécifie la durée de validité minimale du code par tranche de 10 minutes. Une valeur de 1 donne une validité du code entre 10 et 20 minutes, une valeur de 2 entre 20 et 30 minutes, etc. La validité est importante pour minimiser les risques de vol de code à postériori. - Nom : PROP_RESET_PASS_LENGTH
Valeur : entier positif (défaut : 10)
Description : Spécifie la longueur du code de réinitialisation. Une valeur trop faible est sujette aux tentatives d’attaques dites de force brute. Une valeur trop importante est sujette à des erreurs de saisie de la part des utilisateurs.
Réglages de sécurité interne
Des réglages sur les mécanismes de protection intégrés à DigDash sont possibles. Vous pouvez vous référer au document Réglages de sécurité avancés.
Externalisation des paramètres dans le fichier digdash.properties
Tous les paramètres des applications (fichiers .war) de DigDash Enterperise sont personnalisables dans un seul fichier texte au format properties.
Le fichier digdash.properties complet est livré à la racine du dossier d'installation.
Tous les paramètres sont présents mais désactivés.
Pour les activer, supprimez le caractère # en début de ligne.
Les paramètres sont toujours préfixés du nom de l'application concernée (ex : ddenterpriseapi pour les paramètres de l'application ddenterpriseapi.war).
Pour que le fichier digdash.properties soit pris en compte de manière certaine, il faut spécifier son emplacement au lancement du serveur (Tomcat).
- Sous windows avec le serveur Tomcat fourni, aucune intervention nécessaire : le fichier setenv.bat est déjà configuré pour pointer vers le fichier à la racine de l'installation
- Sous linux avec le serveur Tomcat fourni, copiez le fichier digdash.properties dans le dossier /etc/digdash
- Avec votre propre serveur Tomcat, vous devrez éditer le fichier setenv.bat ou setenv.sh pour spécifier l'emplacement de votre fichier digdash.properties.
Voir les chapitres Guide d'installation Windows et Guide d'installation Linux.
Priorité entre les niveaux de paramétrage
Les paramètres sont lus dans l'ordre suivant (dès qu'une valeur est trouvée, les niveaux suivants sont ignorés) :
- Paramètre dans la commande de lancement du serveur Tomcat (-D<context>.<Parameter>=<value>)
- Fichier .properties spécifié dans la commande en ligne du serveur Tomcat (-D<context>.properties.path=/the/path/to/<context>.properties)
- Fichier .properties trouvé dans le dossier de travail du serveur Tomcat (<tomcat workdir>/<context>.properties)
- Paramètre global dans la commande en ligne du serveur Tomcat (-D<Parameter>=<value>)
- Fichier web.xml de chaque application (<context>/WEB-INF/web.xml)
Cloisonnement des paramètres
On appelle "Cloisonnement" la possibilité de cacher les paramètres d'un domaine pour tous les autres domaines d'un déploiement multi-domaines.
Le fichier digdash.properties contient les paramètres de tous les domaines, même ceux qui n'ont aucun lien entre eux.
Pour remédier à ça il est possible, depuis la version 2021R1 patch 20210817, de grouper les paramètres par domain.
Ainsi lors de la visualisation des paramètres via la page "Etat du serveur", seuls les paramètres du même groupe, ou sans groupe, seront visibles.
Prenons l'exemple d'un déploiement avec les domaines suivants :
- ddenterpriseapi_client1, dashboard_client1, studio_client1
- ddenterpriseapi_client2, dashboard_client2, studio_client2
La syntaxe pour grouper les paramètres est la suivante :
[groupe_client1].dashboard_client1.DOMAIN=[...]
[groupe_client1].studio_client1.SERVERURL=[...]
[groupe_client2].ddenterpriseapi_client2.AppDataPath=[...]
[groupe_client2].dashboard_client2.DOMAIN=[...]
[groupe_client2].studio_client2.SERVERURL=[...]
Spécifier les paramètres de journalisation (logging) log4j.properties
Les paramètres de logging sont définis dans un fichier log4j.properties disponible dans chaque application web déployée.
Nous avons ajouté des options sur la ligne de commande de Tomcat pour permettre de spécifier des fichiers de paramétrage de logging externalisés :
-Ddigdash_dashboard.ddlog4j.properties.path="/path/to/log4j.properties"
-Dadswrapper.ddlog4j.properties.path="/path/to/log4j.properties"
Vous pouvez aussi spécifier l’emplacement du fichier de log (global) sans avoir besoin de spécifier un fichier log4j.properties :
Paramètres du Desktop Studio
Le Desktop Studio de DigDash Enterprise a aussi quelques paramètres optionnels spécifiés dans le fichier digdash.properties.
Voir le chapitre Externalisation des paramètres dans un fichier properties
Liste des paramètres :
- Nom : adminconsole.ddserver
Valeur : URL du serveur DigDash Enterprise (défaut : vide)
Description : Spécifie l’URL du serveur auquel le Studio se connectera. Si non spécifié, le Studio utilisera le serveur de l’URL du fichier JNLP. - Nom : domain
Valeur : Nom du domaine DigDash Enterprise
Description : Spécifie le nom du domaine DigDash Enterprise auquel le Studio se connectera. Si non spécifié, le Studio utilisera le domaine spécifié dans la page d’accueil de DigDash Enterprise. - Nom : forceServerDomain
Valeur : Booléen (défaut : false)
Description : Indique au Studio que l’URL du serveur et le domaine sont modifiables (false) ou non (true) via le bouton Avancé dans la fenêtre de login du Studio. Si ce paramètre est activé, il est conseillé de spécifier les paramètres ddserver et domain. - Nom : dashboard
Valeur : Nom de l’application tableau de bord
Description : Permet de spécifier le nom du de l’application du tableau de bord. Si non spécifié, le Studio utilisera le nom d’application spécifié dans la page d’accueil de DigDash Enterprise, par exemple « digdash_dashboard ». - Nom : authMode
Valeur : Mode d’authentification du Studio (défaut : « default »)
Description : Mode d’authentification spécifique du Studio. Il faut que le serveur DigDash Enterprise reflète un mode d’authentification compatible (variable authMethod dans la configuration du serveur) : Consulter les documentations des add-ons liés à l’authentification et au SSO. Les valeurs possibles sont : « default », « NTUser », « NTUserOrLDAP » et « NTUserOrLDAP,loginForm ». - Nom : sslNoPathCheck
Valeur : Booléen (défaut : false)
Description : Utilisé dans le cadre d’une connexion HTTPS. Indique au Studio de ne pas vérifier le chemin de certification du certificat de sécurité. Utilisé pour tester une configuration SSL avec un certificat auto-signé. Ce setting n’est pas conseillé en production. - Nom : sslNoHostNameCheck
Valeur : Booléen (défaut : false)
Description : Utilisé dans le cadre d’une connexion HTTPS. Indique au Studio de ne pas vérifier le nom de domaine Internet. Utilisé pour tester une configuration SSL avec un certificat auto-signé. Ce setting n’est pas conseillé en production.
- Nom : maxHeapSize
Valeur : Quantité mémoire (défaut : en fonction de la JVM du poste client)
Description : Spécifie la quantité de mémoire du poste client allouée au Studio. La syntaxe est <quantité><unité>, où l’unité est une lettre « m » (mégaoctets) ou « g » (gigaoctets). Exemple : maxHeapSize=2048m
Dossiers de données DigDash Enterprise
DigDash Enterprise stocke les données dans différents dossiers. Ce chapitre résume ces dossiers.
Données de configuration
Localisation (par défaut) : Dossier « Application Data » de l’utilisateur qui lance Tomcat (Windows), ou dossier de l’utilisateur (linux).
Contenu : Sous-dossiers contenant les modèles de données, tableaux de bords, portefeuilles de flux, formats, formules, scripts, styles, chaînes de connexions, etc :
- config : données de configuration communes, données de configuration des rôles, sauvegardes, et dossiers web customisés
- datasources : fichiers du serveur de document par défaut
- server : données de configuration des utilisateurs : portefeuille, modèle de données et tableaux de bord personnels, et serveur de documents personnalisé
Modification : digdash.properties, voir le chapitre Changement de l'emplacement des données.
Données générées
Localisation : Sous dossiers cubes et history du dossier de données de configuration.
Contenu : Cubes, historiques de flux :
- cubes : sous-dossiers des cubes générés (un par modèle de données).
- history : historique de tous flux, fichiers javascripts générés (modèle de données, vues de flux).
Modification : Impossible directement. Il faut modifier la localisation du dossier parent (Données de configuration), ou créer des liens.
Données LDAP
Localisation (par défaut) : dossier ldapdigdash dans le répertoire de travail de Tomcat (« workdir »).
Contenu : Fichiers de la partition LDAP contenant les définitions des utilisateurs, des rôles et des droits DigDash
Modification : digdash.properties, voir le chapitre Règlages LDAP (adswrapper) : Port et dossier des données.
Base de données DDAudit
Localisation (par défaut) : répertoire de travail de Tomcat (« workdir »).
Contenu : Fichier de base de données (H2) contenant les tables des données DDAudit.
Modification : digdash.properties (Voir également Déploiement du module d'audit)
Fichiers de journalisation (log)
Localisation (par défaut) : Fichier de log des modules de DigDash Enterprise (ddenterpriseapi, digdash_dashboard, studio, adswrapper).
Le nom est ddenterpriseapi.log par défaut.
Contenu : log applicatif
Modification : log4j.properties (toutes les webapps)(voir chapitre V.5)