Live Security
- Préambule
- Mécanismes traditionnels de personnalisation de DigDash Enteprise
- Nouvelle Approche « Live Security »
Préambule
La fonctionnalité « Live Security » est un moyen supplémentaire pour sécuriser les informations contenues dans les cubes de données. Ceci est généralement appelé Sécurité au niveau ligne (« Row Level Security »). Nous appelons aussi cela la « personnalisation » des cubes et des flux.
Ce document résume les techniques traditionnelles de personnalisation de données et présente une nouvelle technique de personnalisation avancée appelée « Live Security ».
Mécanismes traditionnels de personnalisation de DigDash Enteprise
Dans les versions précédentes la sécurité au niveau ligne est résolue soit par la personnalisation des cubes, soit par la personnalisation des flux via l’utilisation de variables utilisateur (${user.<nomvariable>}). Voici un rappel de ces méthodes traditionnelles de personnalisation.
Personnalisation au niveau du modèle de données (cube)
La sécurité au niveau ligne est résolue à la génération du cube de données via l’utilisation de variables utilisateur (${user.<nomvariable>}) dans la définition de la source de données et du modèle de données. Par exemple en SQL : SELECT * FROM UneTable WHERE pays='${user.pays}' AND service in '${user.services}'.
Dans cet exemple, chaque utilisateur a une variable pays égale à son pays, et une variable services qui est une liste de noms de services séparés par des virgules (Marketing,Ventes,Logistique) auquel l’utilisateur à le droit d’accès.
Ainsi pour différents utilisateurs on génère un cube différent (un par valeur des variables) ne contenant que les données correspondant au « profil de personnalisation » de chaque utilisateur. Si plusieurs utilisateurs ont les mêmes valeurs pour ces variables, on dit qu’ils ont le même profil, alors ils partagent le même cube.
Ce mécanisme est très simple à mettre en place, et permet en général de segmenter la volumétrie des données, et donc la charge mémoire du serveur lors de la consultation. En effet les utilisateurs se connectent rarement tous en même temps sur le serveur, celui-ci n’aura pas besoin de stocker tous les cubes en mémoire à chaque instant.
Un autre avantage est que selon le type de la source de données la règle de sécurisation peut être très avancée. Notre exemple simple de filtrage sur deux colonnes pays et services peut prendre en compte d’autres critères, provenir d’autres tables (qu’on ne souhaite pas intégrer au cube), etc.
Par contre ce mécanisme multiplie le nombre de cubes à générer et donc le nombre de requêtes vers la source de données.
Enfin la règle de sécurisation peut engendrer une redondance de données entre différents cubes, représentant la partie commune des données que plusieurs utilisateurs peuvent voir. Cette partie commune est dupliquée dans plusieurs cubes.
- Avantages : Sécurisation forte, simplicité de mise en œuvre, grande flexibilité (la complexité de sécurisation est dépendante des capacités de la source de données).
- Inconvénients : Plus de requêtes pour la génération des cubes, risque de redondance de données dans plusieurs cubes.
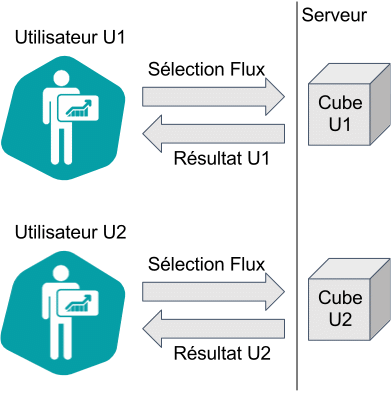
Schéma de personnalisation au niveau du cube
Personnalisation au niveau des flux (graphique/tableau)
Une autre approche plus dynamique est d’utiliser ces variables utilisateur dans la valeur de filtres sur chaque graphique exploitant le cube. Pour reprendre l’exemple précédent, le cube prend ses données d’une source SQL : SELECT * FROM UneTable. Il est unique (non personnalisé) pour tous les utilisateurs, donc volumineux. Dans tous les flux utilisant ce cube on peut ajouter un filtre sur la dimension Pays (règle « égal à » ${user.pays}) et sur la dimension Service (règle « est contenu dans » ${user.services}) . A chaque affichage d’un flux le filtre sera appliqué sur le cube de données pour ne conserver que les lignes auxquelles l’utilisateur a accès. Bien sûr la navigation sur ces dimensions doit être interdite pour l’utilisateur.
L’avantage est qu’on a qu’un seul cube à générer, donc une seule requête vers la source de données.
Par contre le filtrage étant commandé par les flux eux-mêmes lors de la consultation des tableaux de bord il y a un risque de permettre à des utilisateurs d’accéder à des données qui ne les concernent pas. Soit à cause d’un défaut de conception des pages du tableaux de bord, exemple : l’interdiction de la navigation sur une dimension a été omise, soit par manipulation (par un utilisateur expert) des requêtes d’affichage envoyées au serveur.
Enfin un autre inconvénient est une plus faible flexibilité de la règle de sécurisation. Dans cette approche elle dépend directement de ce qui a été stocké dans le cube et ne s’appuie que sur du filtrage de dimension.
- Avantages : Une seule requête pour la génération d’un seul cube
- Inconvénients : Fastidieux à mettre en œuvre (pré-configurer un filtrage sur tous les flux), sécurisation faible, règle de sécurisation limitée.
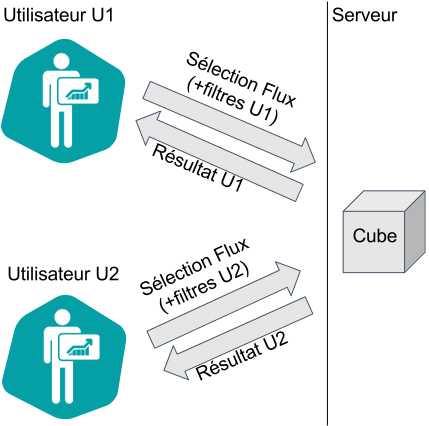
Schéma de personnalisation au niveau du flux
Voici un tableau comparatif de ces deux approches de personnalisation :
| Personnalisation des cubes | Personnalisation des flux | |
| Sécurisation | Forte | Faible |
| Génération des cubes | X cubes générés (1 par « profil de personnalisation ») => X requêtes | 1 cube généré => 1 seule requête |
| Mise en place | Simple | Fastidieuse |
| Flexibilité | En fonction de la source de données (ex : SQL) | Filtrage sur les données du cube uniquement |
Nouvelle Approche « Live Security »
Concept
Cette nouvelle approche, introduite dans la version 2017R1 vise à ne garder que les avantages des deux mécanismes de personnalisation précédents. A savoir une sécurisation forte, un nombre de requêtes nécessaires minimum pour la génération du cube, une mise en place aussi simple que possible tout en conservant un niveau de flexibilité suffisamment élevé.
Elle permet d’ajouter des règles de sécurisation au niveau du modèle de données lui-même, sans démultiplier le nombre de cubes générés et sans obliger à gérer la sécurité au niveau ligne dans les flux.
La règle de sécurisation est exprimée grâce à un script Javascript qui sera exécuté à chaque interrogation du cube sur la sélection entrante. C’est véritablement une transformation de la sélection qui peut être faite. Aussi bien du filtrage simple analogue à l’approche « personnalisation de flux » que de la transformation plus complexe en fonction du profil de l’utilisateur. Par exemple, changer un niveau d’exploration, supprimer un axe, une ou plusieurs mesure, etc.
Coté sécurisation, cette transformation est appliquée avant le traitement de la sélection coté serveur et ne dépend que du profil de l’utilisateur. Il n’y a aucun moyen pour un utilisateur, même expert, d’altérer ce processus comme pour la personnalisation des flux.
- Avantages : Une seule requête pour la génération d’un seul cube, sécurisation forte, grande flexibilité (transformation potentiellement totale de la sélection du flux)
- Inconvénients : Mise en place complexe (Javascript)
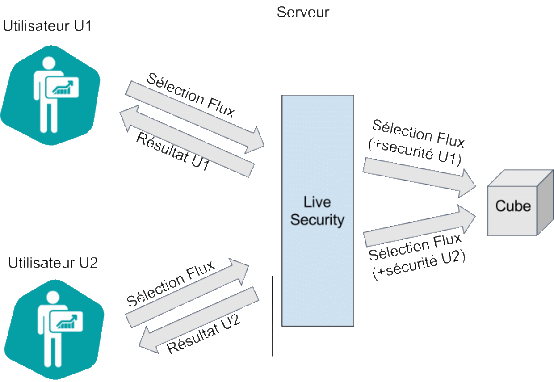
Schéma de personnalisation « Live Security »
Voici un tableau comparatif reprenant cette nouvelle approche avec les deux précédentes approches de personnalisation :
| Personnalisation des cubes | Personnalisation des flux | Personnalisation « Live Security » | |
| Sécurisation | Forte | Faible | Forte |
| Génération des cubes | X cubes générés (1 par « profil de personnalisation ») => X requêtes | 1 cube généré => 1 seule requête | 1 cube généré => 1 seule requête |
| Mise en place | Simple | Fastidieuse (par flux) | Avancée |
| Flexibilité | En fonction de la source de données (ex : SQL) | Filtrage sur les données du cube uniquement | Transformation de la sélection |
Mise en place
Ce chapitre décrit comment mettre en place le mécanisme Live Security au travers d’un exemple standard de filtrage de dimension.
L’exemple se base sur une source de données qui contient au moins deux colonnes pays et service et des colonnes de valeurs (mesures). Chaque utilisateur est assigné à un pays et à un ou plusieurs services et ne verra donc que les chiffres qui s’y rapportent. Certains utilisateur peuvent avoir le droit de voir tous les pays et/ou tous les services.
Prérequis
Chaque utilisateur a deux variables dans le LDAP : pays et services qui définissent son périmètre de sécurité. Chacune des deux variables peut être vide, cela signifie que l’utilisateur peut voir tous les pays et/ou services. La variable services peut être une liste de noms de services séparés par des virgules (pas d’espace après les virgules).
Exemple :
Utilisateur U1 :
pays = 'fr'
services = 'Marketing,Ventes'
Utilisateur U2 :
pays = 'de'
services = (chaîne vide)
Modèle de données
La source de données est une source SQL sur laquelle on exécute la requête suivante :
SELECT pays, service, val1, val2 FROM UneTable
On peut noter qu’il n’y a pas de clause WHERE dans cette requête car le but est de générer un cube unique contenant toutes les données pour tous les utilisateurs.
Le modèle de données contient donc deux dimensions et deux mesures.
L’activation du Live Security se fait dans l’écran de configuration du modèle de données, onglet Avancé :
- Choisissez le Mode de traitement du cube : Toujours sur le serveur
- Cliquez sur le bouton Editer… au niveau de la boite de sélection de la Fonction de transformation de sélection.
- Choisissez Script dans le Type de fonction.
Vous pouvez maintenant saisir un script de transformation des sélections faites sur le cube correspondant à ce modèle de données.
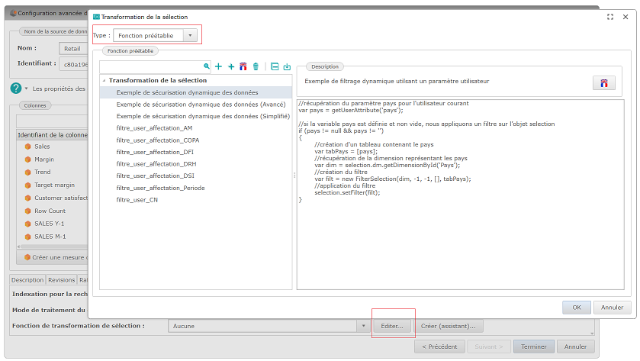
Script
Le script à écrire est le corps d’une fonction Javascript qui prend en paramètre un objet « selection ». Cet objet représente la description du résultat que l’on souhaite obtenir du cube (opération « d’aplatissement »). Cet objet complexe définit les axes souhaités, les dimensions, les filtres, les mesures et d’autres paramètres propres à chaque type de flux (graphique, tableaux…). Ce qui nous intéresse dans cet exemple ce sont les paramètres de filtrage de dimension. Le but est de transformer cette sélection afin d’y inclure deux filtres « forcés », un sur le pays de l’utilisateur et un sur ses services, si l’utilisateur a des variables définies (non vides) pour le pays et/ou les services.
Commençons par récupérer la valeur de la variable de l’utilisateur pays en utilisant la fonction getUserAttribute(‘<nomvariable>’) :
Ensuite, si la variable pays est définie et non vide, nous appliquons un filtre sur l’objet selection :
if (pays != null && pays != '')
{
var tabPays = [pays]; //création d'un tableau contenant le pays
var dim = selection.dm.getDimensionById('Pays');
var filt = new FilterSelection(dim, -1, -1, [], tabPays);
selection.setFilter(filt);
}
Explication : La construction du filtre se fait avec l’aide de l’instruction new FilterSelection(Dimension, nomHierarchie, nomNiveau, [ ], tableauMembres) :
- Dimension : L’objet dimension peut-être récupéré directement dans le modèle de données accessible via selection.dm, grâce à la fonction getDimensionById(dimId).
- nomHierarchie et nomNiveau : Ensuite, dans cet exemple, nous filtrons directement les membres racines de la dimension, il n’y a pas de hiérarchie ni de niveau à préciser (...-1, -1...).
- [ ] (tableau vide) : Utilisé de manière interne, ne pas modifier.
- TableauMembres : Enfin, un filtre sur une dimension peut avoir plusieurs membres sélectionnés, il faut donc lui passer un tableau de membres (ici tabPays). Pour le pays, comme l’utilisateur n’en a qu’un, le tableau ne contient qu’un élément.
Puis nous appliquons ce filtre à la sélection par selection.setFilter(…).
Enfin, on fait la même chose pour la variable services qui représente une liste de services, qu’on traite spécifiquement grâce à la fonction Javascript split(). Elle découpe une chaîne de caractères en un tableau de chaînes de caractères selon un caractère séparateur (la virgule dans notre cas) :
var services = getUserAttribute('services');
if (services != null && services != '')
{
var tabServices = services.split(',');
var dim = selection.dm.getDimensionById('Service');
var filt = new FilterSelection(dim, -1, -1, [], tabServices);
selection.setFilter(filt);
}
Utilisation
Il ne reste plus qu’à créer un flux sur ce modèle de données et à le placer dans une page de tableau de bord.
Si on ne cache pas les dimensions pays et service dans le tableau de bord (ou dans le flux) il sera toujours possible de filtrer sur une de ces dimensions. Cependant le filtre sera écrasé par le script de Live Security si l’utilisateur a une valeur non vide pour sa variable pays ou services. Au final le filtrage sur ces dimensions dans le tableau de bord n’est utile que pour les utilisateurs ayant le droit de tout voir c’est à dire ceux qui ont une valeur vide dans leur variable pays et/ou services.
Référence API
Cette fonctionnalité est très récente, son API est susceptible d’évoluer dans de futures versions. Pour l’instant il n’y a que quelques méthodes recommandées pour manipuler une sélection. Ces méthodes sont décrites dans ce paragraphe.
Récupération d’informations utilisateurs
Description : Retourne l'attribut LDAP attr de l'utilisateur. Aussi appelé « variable d’utilisateur ».
Exemple :
(Chaîne) getSessionAttribute (attr)
Description : Retourne l'attribut Session attr de l'utilisateur pour la session courante.
L’utilisation de variable de session est couverte dans le document Tutoriel variables de session.
Exemple :
Récupération d’informations de la sélection ou du modèle de données courant
Description : Retourne la valeur de la variable du modèle (DDVar) correspondante. Ces variables sont définies dans le modèle de données et correspondent à un contrôle dans la page de tableau de bord.
Exemple :
(Dimension) selection.dm.getDimensionById(dimId)
Description : Retourne un objet Javascript correspondant à la dimension d’identifiant dimId. Retourne null si cette dimension n’est pas dans modèle courant. Cet objet est nécessaire à d’autres fonctions, par exemple pour la construction d’un filtre.
Exemple :
Transformation de la sélection
Description : Retourne un objet Javascript correspondant au filtre souhaité sur la dimension en paramètre, dans une hiérarchie et un niveau donné (-1 si pas de hiérarchie/niveau) et avec les membres spécifiés. Cet objet est nécessaire à d’autres fonctions, par exemple pour l’application du filtre sur la sélection.
Exemple :
void selection.setFilter(filtre)
Description : Applique un filtre sur la sélection courante. Écrase le filtre existant sur cette dimension s’il y en avait un.
Exemple :
void setDDVar(variable, valeur)
Description : Modifie la valeur d’une variable de modèle (DDVar) pour la sélection courante. La valeur de la variable n’est pas modifiée de manière persistante, seulement pour cette sélection.
Exemple :