Configuración avanzada de parámetros del sistema
- Configuración Tomcat
- Configuración avanzada de rendimiento
- Servicio de mantenimiento automático
- Uso de varios servidores en modo "Cluster"
- Otras configuraciones avanzadas
- Cambiar la ruta de los archivos de datos
- Configuración de LDAP (adswrapper): puerto y directorio de datos
- Configuración avanzada del editor y de la consultación de cuadros de mandos
- Configuración de seguridad interna
- Externalización de parámetros en un archivo digdash.properties
- Especificar los parámetros de registro (logging) log4j.properties
- Configuración del Desktop Studio
- Directorios de datos DigDash Enterprise
A continuación, <digdash.appdata> se refiere a la ubicación que ha elegido para guardar los datos (fuentes, gráficos, formatos, ...).
Debe ingresarse en el archivo digdash.properties bajo el parámetro digdash.appdata o ddenterpriseapi.AppDataPath (consulte la Guía de instalación de Windows Guía de instalación de Windows o la Guía de instalación de Linux)
También puede verlo en la página "Estado del servidor" de las páginas de administración de su servidor (con el servidor encendido).
Este documento describe las configuraciones avanzadas de los parametros del servidor DigDash Enterprise (DDE).
Los siguientes archivos seran modificados:
- server.xml
- Ubicación (Tomcat global) :
<DDE Install>/apache-tomcat/conf/server.xml
- Ubicación (Tomcat global) :
- web.xml
- Ubicación (Tomcat global) :
<DDE Install>/apache-tomcat/conf/web.xml
- Ubicación (Tomcat global) :
- system.xml
- Ubicación :
<digdash.appdata>/Enterprise Server/ddenterpriseapi/config/system.xml
- Ubicación :
- digdash.properties
- Ubicación :
<DDE Install>/digdash.properties
o /etc/digdash/digdash.properties (en Linux)
o la ubicación personalizada que hubiera configurado.
- Ubicación :
- web.xml (este metodo es obsoleto, use el archivo digdash.properties)
- Ubicación (ddenterpriseapi) :
<DDE Install>/apache-tomcat/webapps/ddenterpriseapi/WEB-INF/web.xml - Ubicación (dashboard) :
<DDE Install>/apache-tomcat/webapps/digdash_dashboard/WEB-INF/web.xml - Ubicación (adminconsole) :
<DDE Install>/apache-tomcat/webapps/adminconsole/WEB-INF/web.xml - Ubicación (studio) :
<DDE Install>/apache-tomcat/webapps/studio/WEB-INF/web.xml - Ubicación (adswrapper) :
<DDE Install>/apache-tomcat/webapps/adswrapper/WEB-INF/web.xml
- Ubicación (ddenterpriseapi) :
- setenv.bat (Windows)
- Ubicación : <DDE Install>/configure/setenv.bat
- setenv.sh (Linux)
- Ubicación : <DDE Install>/apache-tomcat/bin/setenv.sh
- dashboard_system.xml
- Ubicación : <digdash.appdata>/Application Data/Enterprise Server/dashboard_system.xml
Configuración Tomcat
Asignar más memoria a Tomcat
Archivo modificado: setenv.bat osetenv.sh
- En Windows: setenv.bat ubicado en el directorio <install DD>/configure.
- En Linux: setenv.sh ubicado en el directorio <install DD>/apache-tomcat/bin
Ubique las siguientes lineas al inicio del archivo:
set JVMMX=512
Cambie las 2 apariciones de "512" por la cantidad de memoria (megabytes) que desea asignar a Tomcat. Por ejemplo, "4096" asignará 4 GB de memoria a Tomcat.
set JVMMX=4096
Cambiar los puertos de red de Tomcat
Archivo modificado: server.xml
Si uno de los puertos que necesita Tomcat ya está siendo utilizado por otro proceso, no se iniciará. Es necesario verificar la disponibilidad de los puertos y si es necesario reconfigurar Tomcat. Por defecto, están configurados los siguientes 3 puertos: 8005, 8080 y 8009. Para modificarlos:
- Abra el directorio <install DDE>\apache-tomcat\conf y luego edite el archivo server.xml
- Busque y reemplace los valores de los puertos 8005, 8080 y 8009 con los números de puerto disponibles en el sistema
Cambiar la duraciónde vida de las sesiones inactivas (timeout)
Archivo modificado: web.xml (configuración global de Tomcat ubicado en la ubicación <DDE Install>/apache-tomcat/conf/web.xml)
Busque las siguientes líneas en el archivo:
<session-timeout>30</session-timeout>
</session-config>
Cambie el valor para modificar la duración en minutos de una sesión inactiva (tiempo de espera). Por defecto, el tiempo de espera es de 30 minutos.
Cambiar el número máximo de consultas simultáneas
Archivo modificado: server.xml
De forma predeterminada, Tomcat no aceptará más de 200 solicitudes simultáneas. Esta configuración puede resultar limitante en el caso de una implementación para una gran cantidad de usuarios (varios miles o millones), o durante un banco de rendimiento (por ejemplo, jmeter) que ejecuta cientos o miles de solicitudes simultáneas.
Para aumentar este límite, debe agregar un atributo maxthreads en el elemento Conector correspondiente al conector utilizado.
Ejemplo cuando el conector utilizado es http (no hay Apache en el front-end):
Ejemplo cuando el conector utilizado es AJP (hay un Apache en el front-end):
Activar la compresión HTTP
Archivo modificado: server.xml
La compresión HTTP reduce el consumo de ancho de banda de la red al comprimir las respuestas HTTP. De forma predeterminada, esta opción no está habilitada en Tomcat, aunque todos los navegadores modernos la admiten.
Esta opción a veces puede ahorrar hasta un 90% de ancho de banda en ciertos tipos de archivos: HTML, Javascript, CSS. Consumiendo poca CPU en el servidor y el cliente.
En el archivo server.xml, agregue los parámetros compression="on" y compressionMinSize="40000" en el conector HTTP/1.1:
Ejemplo :
El atributo compressMinSize define un tamaño de respuesta mínimo (en bytes) por debajo del cual no se utiliza la compresión. Le recomendamos que especifique este atributo a un valor suficiente para no comprimir archivos que ya son muy pequeños (iconos PNG, etc.).
Configuración avanzada de rendimiento
Archivo modificado: system.xml
Ejemplo de sintaxis XML:
Threads utilizados para la ejecución de flujos programados
Modifica el número de subprocesos (threads) utilizados para la ejecución de flujos programados (planificador) o en evento.
Propriedades disponibles:
- Nombre: MAX_TP_EXECSIZE
- Valor: entero > 0 (por defecto: 16)
Descripción: Número máximo de subprocesos para procesar tareas de sincronización. - Nombre : TP_SYNC_PRIORITY
Valor: cadena de carácteres("flow" o "none") (por defecto: flow)
Descripción: Mode de priorité des tâches.- Valor flow :Procese la sincronización de la secuencia lo antes posible después de que se haya generado el cubo para esa secuencia.
- Valor none : el flujo se sincronizará cuando haya espacio en la cola de subprocesos. Este parámetro solo se tiene en cuenta cuando el parámetro TP_PRIORITYPOOL se establece en true.
- Nombre : TP_SYNC_GROUPFLOWBYCUBE
Valor: booleano (por defecto : false)
Descripción: Cambia el modo de procesamiento de trabajos en espera.- Valor false: las tareas de procesamiento de flujo se distribuyen entre todos los subprocesos disponibles independientemente del cubo utilizado. Esto conduce a un procesamiento paralelo de los flujos en detrimento de los cubos, recomendado cuando hay pocos cubos pero muchos flujos.
- Valor true: agrupa el procesamiento de flujos del mismo cubo en un solo thread. Esto conduce a un procesamiento paralelo de los cubos en detrimento de los flujos, recomendado cuando hay muchos cubos diferentes y pocos flujos utilizando los mismos cubos. Este parámetro solo se tiene en cuenta cuando el parámetro TP_PRIORITYPOOL es true.
Threads utilizados para ejecutar flujos interactivos
Modifica el número de subprocesos (threads) utilizados para la ejecución interactiva de flujos (Studio, dashboard, móvil, etc.).
Propriedades disponibles:
- Nombre: MAX_TP_PLAYSIZE
Valor: entero > 0 (por defecto : 16)
Descripción: Número máximo de subprocesos para procesar tareas de sincronización. - Nombre: TP_PLAY_PRIORITY
Valor: chaine ("flow" ou "none") (por defecto: flow)
Descripción: Mode de priorité des tâches.- Valor flow :Procese la sincronización de la secuencia lo antes posible después de que se haya generado el cubo para esa secuencia.
- Valor none : el flujo se sincronizará cuando haya espacio en la cola de subprocesos. Este parámetro solo se tiene en cuenta cuando el parámetro TP_PRIORITYPOOL se establece en true.
- Nombre: TP_PLAY_GROUPFLOWBYCUBE
Valor: booleano (por defecto : false)
Descripción: Cambia el modo de procesamiento de trabajos en espera.- Valor false: las tareas de procesamiento de flujo se distribuyen entre todos los subprocesos disponibles independientemente del cubo utilizado. Esto conduce a un procesamiento paralelo de los flujos en detrimento de los cubos, recomendado cuando hay pocos cubos pero muchos flujos.
- Valor true: agrupa el procesamiento de flujos del mismo cubo en un solo thread. Esto conduce a un procesamiento paralelo de los cubos en detrimento de los flujos, recomendado cuando hay muchos cubos diferentes y pocos flujos utilizando los mismos cubos. Este parámetro solo se tiene en cuenta cuando el parámetro TP_PRIORITYPOOL es true.
Límites de tiempo para eliminar cubos en la memoria
Cambia la forma en que el Administrador de cubos elimina los cubos no utilizados en la memoria.
La siguiente configuración cambia la forma en que se eliminan los cubos que no se han utilizado durante algún tiempo, incluso si la sesión todavía está activa.
Propriedades disponibles:
- Nombre: CUBE_TIMEOUT_INTERACTIVE
Valor: minutos> 0 (por defecto: 10 minutos)
Descripción:Duración del período de inactividad de un cubo cargado en modo interactivo (navegación del cubo en el servidor) - Nombre: CUBE_TIMEOUT_SYNC
Valor: minutos> 0 (por defecto: 4 minutos)
Descripción: Duración del período de inactividad de un cubo cargado en modo programado (generación de un flujo programado) - Nombre: CUBE_TIMEOUT_PERIOD
Valor: minutos> 0 (por defecto: 2 minutos)
Descripción: El intervalo para comprobar la actividad del cubo debe ser al menos CUBE_TIMEOUT_SYNC / 2
Rendimiento de los cubos de datos
Estos ajustes afectarán el procesamiento interactivo de cubos de datos (aplanamiento en cubos de resultados durante la visualización). Esta configuración no afecta la generación de cubos de datos.
Propriedades disponibles:
- Nombre: CUBEPART_MAXSIZEMB
Valor: megabytes > 0 (por defecto: 100 MB)
Descripción: Tamaño de un cubo compartido en megabytes. Una parte del cubo es una parte del cubo de datos que se puede procesar (aplanar) en paralelo o distribuir a otros servidores DigDash Enterprise en modo de clúster (consulte el capítulo "Uso de varios servidores en modo de clúster" en este documento). - Nombre: TP_MCUBESIZE
Valor: threads > 0 (por defecto: 64 threads)
Descripción: Tamaño de la cola de subprocesos utilizada para el procesamiento paralelo de recursos compartidos de cubo. Los cubos grandes (por ejemplo, varios millones / billones de líneas) son procesados en paralelo por el servidor y / o por otros servidores (en modo cluster). Este parámetro es el número de unidades de procesamiento en paralelo (subprocesos) en una máquina. Cada parte del cubo ocupa una unidad de la cola mientras se procesa, si la cola está llena, las unidades adicionales se ponen en espera. - Nombre: MCUBE_ROWS_PER_THREAD
Valor: lignes > 0 (por defecto: 100000)
Descripción: Este es el límite del número de filas de un cubo de datos más allá del cual el servidor DigDash Enterprise activará el procesamiento paralelo de las partes del cubo (si hay más de una parte para este cubo). Por debajo de este límite, el procesamiento del cubo no es paralelo sino secuencial.
Otros parámetros de rendimiento
Los siguientes parámetros se utilizan para analizar u optimizar el rendimiento del sistema.
Propriedades disponibles:
- Nombre: LOW_MEMORY_THRESHOLD
Valor: porcentaje> 0 (por defecto: 10%)
Descripción: Este es el umbral como porcentaje de memoria libre restante por debajo del cual el sistema emitirá una alerta de memoria baja. Esta alerta está visible en la página de estado del servidor durante 24 horas. También se registra en la base de datos DDAudit si se inicia el servicio de auditoría del sistema.
Por último, también se activa un evento DigDash cuando se alcanza el umbral: SYSCHECK_LOWMEM. Un ejemplo del uso de este evento se da en el documento de implementación del módulo DDAudit. - Nombre: TP_PRIORITYPOOL
Valor: booleano (por defecto: true)
Descripción: Utiliza un grupo de subprocesos de actualización administrados por prioridad para actualizaciones de cubos y flujos. Ver los parámetros TP_PLAY_GROUPFLOWBYCUBE, TP_SYNC_GROUPFLOWBYCUBE, TP_PLAY_GROUPFLOWBYCUBE, TP_SYNC_GROUPFLOWBYCUBE
Servicio de mantenimiento automático
DigDash Enterprise proporciona un servicio de mantenimiento que consta de:
- Un limpiador de archivos (también llamado Files GC) que limpia todos los archivos no utilizados: archivos históricos antiguos, cubos y otros archivos dependientes de los flujos.
- Una generacion automatica de una copia de seguridad de la configuración
Limpiador de archivos
El limpiador limpia los archivos no usados por las carteras de roles y de usuarios.
El limpiador analiza los índices de todos los usuarios, así como el disco, para encontrar archivos que ya no están vinculados a los índices. Los archivos identificados se eliminan. Los archivos eliminados son: archivos de cubos (.dcg), archivos js de cubos (cube_data_id.js), modelos (cube_dm_id.js) y flujos(cube_view_id_js).
Esta operación tiene la ventaja de liberar espacio en disco y potencialmente acelerar las búsquedas de archivos js, que pueden llegar a ser importantes en grandes volúmenes (número de cubos personales * número histórico> 100.000)
Dependiendo de la antigüedad del servidor y del tamaño de los archivos en cuestión (número de actualizaciones realizadas, etc.), la operación puede llevar mucho tiempo cuando se ejecuta por primera vez (en algunas implementaciones con muchos usuarios y muchos cubos, de una a dos horas).
Luego, si la limpieza se realiza de forma periódica, el tiempo de ejecución será menor. Este tiempo depende en gran medida del rendimiento del sistema de archivos y de la máquina, lo que dificulta la estimación.
Copia de seguridad automatizada
Se realiza una copia de seguridad automática antes de limpiar los archivos. El archivo generado se copia en el directorio de configuración: <digdash.appdata>/Enterprise Server/<dominio>/backups/<fecha del día>.zip
Por defecto, el mantenemiento occure cada dia a la medianoche.
Activación, desactivación y / o limpieza en el arranque
Este párrafo describe cómo activar y programar el servicio de mantenimiento.
La activación del limpiador de archivos se puede realizar de dos formas:
1- Desde la página del estado del servidor:
La página Estado del servidor se puede consultar desde la página de inicio de DigDash Enterprise, haciendo clic sucesivamente en los botones Configuración y Estado del servidor.
En la seccion Estado del limpiador de archivos, haga clic en la flecha verde al lado de Limpiador de archivos iniciados para iniciar el limpiador:

La próxima limpieza se realizará a medianoche. Para iniciar el limpiador de archivos de inmediato, haga clic en el icono .
.
2- Desde el archivo digdash.properties :
Archivo modificado: digdash.properties
Consulte el capítulo Externalización de parámetros en un archivo digdash.properties para realizar esta manipulación.
Propriedades disponibles:
- Nombre: ddenterpriseapi.startCleaner
Valor: booleano (por defecto: false)
Descripción:- true : limpieza automática de archivos programada.
Nota: el tiempo de limpieza se define en system.xml, mediante el parámetro FILESGC_SCHEDXML.
El tiempo de limpieza predeterminado (si no se especifica ninguno en system.xml, FILESGC_SCHEDXML) es diario a las 0:00 - false (por defecto) : limpieza automática de archivos desactivada
- true : limpieza automática de archivos programada.
- Nombre: ddenterpriseapi.cleanOnStart
Valor: booleano (por defecto: false)
Descripción:- true : limpia los archivos no utilizados cuando se inicia el servidor (archivos de historial, cubos, archivos de resultados, ...)
- false (por defecto) : no limpia los archivos no utilizados cuando se inicia el servidor
- Nombre: ddenterpriseapi.autoBackup
Valor: booleano (por defecto: false)
Descripción:- *. true : activa la copia de seguridad automática programada
- false (por defecto) : no activa la copia de seguridad automática programada
Programación y opciones de mantenimiento automático
Archivo modificado: system.xml.
Propriedades disponibles:
- Nombre: FILESGC_SCHEDXML
Valor: frase XML (codificada) (por defecto : ninguna)
Descripción: Este parámetro contiene una frase codificada en XML que describe la frecuencia de programación.
Ejemplo:
value="<Schedule frequency="daily"
fromDay="11" fromHour="0"
fromMinute="0" fromMonth="7"
fromYear="2011" periods="1"
time="0:0"/>"></Property>
- Nombre: FILESGC_SESSIONSCHECK
Valor: true/false (booleano) (por defecto: ninguna, vale false)
Descripción: Este parámetro indica si el limpiador de archivos debe comprobar si hay sesiones activas antes de iniciar (true) o si se inicia independientemente del estado de las sesiones activas (false). En el último caso, todas las sesiones se desconectarán instantáneamente.
Ejemplo:
- Nombre: USEAUTOBACKUP
Valor: true/false (booleano) (por defecto: ninguna, vale false)
Descripción: Esta configuración especifica si el serivio de mantenimiento también realiza una copia de seguridad completa de la configuración antes de ejecutar la limpieza de archivos.
Uso de varios servidores en modo "Cluster"
Para gestionar un mayor volumen de datos (mil millones de líneas), es posible utilizar varios servidores en modo "Cluster". Cada servidor se convierte en un nodo informático del clúster.
Este último incluye un servidor maestro y servidores esclavos.
El servidor maestro se encarga de administrar modelos, documentos, roles, usuarios, sesiones y generar cubos y flujos (actualización). Idéntico a un servidor de Digdash Enterprise en el modo estándar de una sola máquina.
Los servidores esclavos adicionales solo se utilizan para ayudar en el aplanamiento interactivo de grandes cubos de datos, al mostrar flujos, filtrar, etc.
Hay dos arquitecturas de agrupación en clústeres en DigDash Enterprise:
- Agrupación interna: descrita en este capítulo
- Clúster de Apache Ignite: Módulo de clúster de Apache Ignite
Instalar DigDash Enterprise en modo "Cluster"
Requisito: varias máquinas conectadas entre sí por la red
Servidor maestro (en la máquina más potente del clúster)
- Instalación estándar de DigDash Enterprise (consulte la Guía de instalación de Windows o el Guía de instalación de Linux).
- Iniciar el servidor normalmente con start_servers.bat
Servidor esclavo (en cada una de las otras máquinas del clúster)
- Instalación estándar de DigDash Enterprise (consulte la Guía de instalación de Windows o el Guía de instalación de Linux).La diferencia es que un servidor esclavo no necesita una licencia para servir como unidad de computación para el clúster, ni un directorio LDAP, ni la aplicación digdash_dasboard cuya el war se puede eliminar de Tomcat.
- Iniciar solo el módulo Tomcat, con start_tomcat.bat o apache_tomcat/bin/startup.sh
Configurar el clúster
Procedimiento para repetir en cada servidor del clúster
- Con un navegador, conéctese a la página de inicio de DigDash Enterprise (ejemplo: http://<servidor>:8080)
- Haga clic en Configuración, y luego en Parámetros servidor
- Inicie sesión como administrador de DigDash Enterprise (admin / admin de forma predeterminada) para mostrar la página de configuración del servidor
- En el menu a la izquierda, haga clic en Configuración del clúster
- Ingrese los diferentes campos en función de cada máquina del servidor (ver explicaciones a continuación)
Sección Rendimiento del sistema

La sección Rendimiento del sistema define las capacidades de la máquina actual en el clúster. Los parámetros Número de CPU, Puntuación de CPU y Memoria asignada permiten distribuir la carga de cálculo de la mejor manera posible.
- Número de CPU: el número de procesadores * número de núcleos en cada procesador. Potencialmente multiplicado por un factor si los procesadores se benefician de la tecnología Hyper-Threading. Predeterminado -1, se basa en los datos devueltos por el sistema operativo
- Puntuación CPU: es una puntuación entre 1 y 10 que permite poner el rendimiento de un nodo del clúster en relación con los demás (caso de un clúster heterogéneo). Por defecto, -1 da una calificación promedio (5).
- Memoria asignada: la fracción de la memoria máxima permitida cuando se usa el servidor como unidad de cálculo. Este valor es menor o igual que la memoria asignada al servidor Tomcat. El valor predeterminado -1 permite el uso de toda la memoria.
Sección Clústeres autorizados
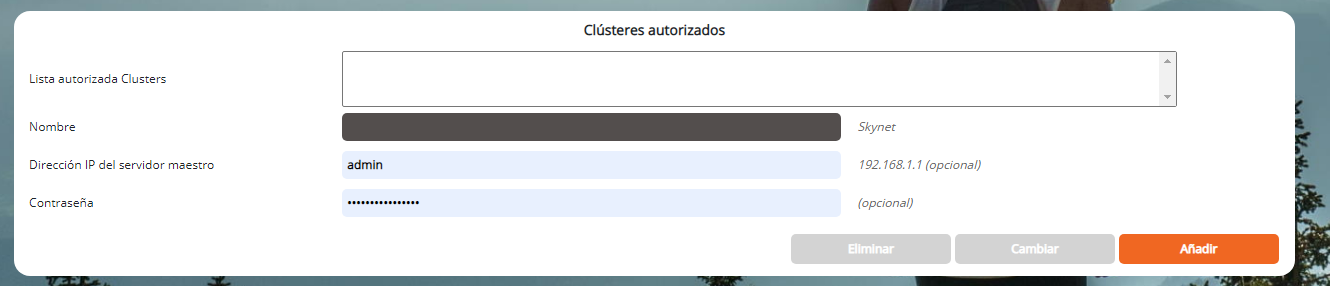
La sección Clústeres autorizados le permite especificar si la máquina actual se puede utilizar como esclava de uno o más clústeres y, de ser así, cuáles. De hecho, una máquina se puede utilizar para varios clústeres de DigDash Enterprise. Esta sección restringe este uso como esclavo a solo ciertos grupos (lista de selección),
También es en esta sección que definimos la Contraseña del servidor actual en el clúster seleccionado. Sin una contraseña, el servidor no puede ser esclavo en este clúster.
Para agregar un clúster autorizado para usar este servidor esclavo:
- Nombre: nombre del clúster (arbitrario)
- Dirección IP del servidor maestro: dirección IP del servidor maestro del clúster autorizado para usar este servidor como esclavo (por ejemplo: http://192.168.1.1)
- Contraseña: contraseña de esclavo en el contexto del clúster seleccionado
- Haga clic en el botón Añadir para agregar este clúster a la lista de clústeres autorizados
Sección Definición del clúster
Para completar solo en el servidor maestro del clúster
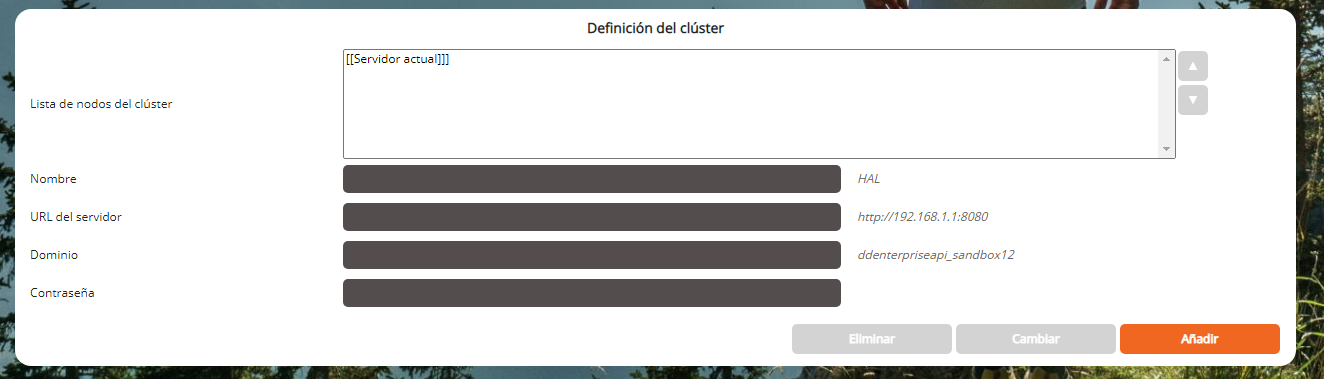
La sección Definición de clúster solo se aplica al servidor maestro del clúster. Aquí es donde creamos un clúster enumerando los servidores esclavos del clúster, así como el maestro en sí (en la lista de selección). El servidor maestro es implícitamente el servidor a través del cual se conectó a esta página.
Para agregar una máquina esclava al clúster:
- Nombre: nombre de la máquina esclava (arbitrario)
- URL del servidor: URL del servidor esclavo (por ejemplo: http://192.168.1.123:8080)
- Dominio: dominio de DigDash Enterprise (por defecto ddenterpriseapi)
- Contraseña: contraseña del esclavo como la escribió anteriormente al configurar la máquina esclava (sección Clústeres autorizados, campo Contraseña)
- Haga clic en el botón Añadir para agregar esta máquina a su clúster.
Utilisation de plusieurs maîtres dans un cluster
Algunas implementaciones requieren el uso de varios servidores maestros dentro de un solo "clúster". Por ejemplo, en el caso de un balanceador de carga HTTP que envía sesiones de usuario a uno o otro servidor maestro. Este modo es compatible con DigDash mediante la definición de varios clústeres idénticos (uno por servidor maestra). La lista de los servidores (sección de definición de clúster) debe ser estrictamente idéntica para todas las definiciones de clúster. Por eso es posible cambiar el orden de los servidores en esta lista.
Ejemplo: Queremos definir un clúster que consta de dos servidores A y B. Cada una de las dos máquinas es maestra y esclava de la otra.
Debemos definir no uno, sino dos clústerse A y B:
En la definición del cluster A :
- Servidor actual : Servidor A (maestro de este clúster)
- Servidor B (esclavo de este clúster)
En la definición del cluster B :
- Servidor A (esclavo de este clúster)
- Servidor actual: Servidor B (maestro de este clúster)
Vemos que en el clúster B, el maestro (B) no es el primer servidor de la lista. Lo importante aquí es que la lista de los servidores A, el servidor B es de hecho el mismo en ambos clústeres (independientemente de su función específica dentro de su respectivo clúster).
Configuración avanzada específica del clúster
Archivo modificado: system.xml
Ejemplo de sintaxis XML:
Propriedades disponibles:
- Nombre: CUBE_UPLOAD_MODE
Valor: entero: 0, 1 ou 2 (por defecto: 1)
Descripción: Especifica si los recursos compartidos del cubo deben descargarse del servidor maestro a los servidores esclavos cuando un usuario interactúa con el cubo (1), cuando el servidor maestro genera el cubo (2) o nunca (0);
Ver también el próximo capítulo : "Uso del clúster". - Nombre: CLUSTER_TIMEOUT
Valor: entero: (milisegundos, por defecto: 30000)
Descripción: Especifica el tiempo de espera para todas las solicitudes dentro del clúster (entre el maestro y los esclavos), con la excepción de la solicitud para verificar la disponibilidad de un esclavo (ver más abajo) - Nombre: CLUSTER_CHECK_TIMEOUT
Valor: entero: (milisegundos, por defecto: 5000)
Descripción: Especifica el tiempo de espera para la solicitud de verificación de disponibilidad del esclavo. Este tiempo de espera es más corto para evitar bloquear el maestro durante demasiado tiempo en caso de que un esclavo se desconecte de la red.
Uso del clúster
En una implementación de clúster simple, no hay nada más que hacer que lo que se ha escrito anteriormente.
Aun así, existen algunos detalles interesantes que pueden ayudar a mejorar el rendimiento de un clúster.
El clúster se utiliza según el tamaño del cubo de datos. Por debajo de cierto umbral, según el cubo, el servidor maestro y los esclavos, es posible que no se utilice el clúster. Por otro lado, si el tamaño de uno o más cubos de datos se vuelve grande, por ejemplo más allá de varios cientos de millones de líneas, estos se cortarán en varias partes y su cálculo (aplanamiento) se distribuirá en paralelo en todos los procesadores. disponible en el clúster para disminuir el tiempo de respuesta general. Y esto por cada aplanamiento de un cubo grande por parte de un usuario del tablero, móvil, etc.
Cabe señalar que la generación de cubos es responsabilidad del servidor maestro. Los esclavos intervienen solo durante el aplanamiento interactivo de cubos ya generados (ej: visualización de un flujo, filtrado, taladrado ...)
Las piezas del cubo se envían a los esclavos a pedido (si aún no las tienen). Esto puede provocar una ralentización del sistema en un primer aplanamiento solicitado por un usuario, en particular si el ancho de banda de la red es bajo (<1 gigabit).
Sin embargo, existen diferentes formas de evitar esta congestión de la red. Aquí hay algunas sugerencias:
Una primera forma es tener la carpeta de cubos (subcarpeta de Application Data / Enterprise Server / ddenterpriseapi por defecto) en un disco de red accesible para todos los servidores del clúster. Por ejemplo, a través de un enlace simbólico (Linux, NFS). Este vínculo debe establecerse para todos los servidores del clúster. El principio es que el servidor maestro generará los cubos en esta carpeta de red, y cuando un usuario interactúa con el sistema, el maestro y los esclavos tendrán una vista común de los cubos. Dado que los cubos del disco se leen solo una vez en el ciclo de vida de un cubo (cubo en memoria), el impacto de la carpeta de red en el rendimiento es insignificante.
Otra forma es utilizar una herramienta de terceros para la sincronización automática de carpetas entre varios servidores, que podrá copiar toda la carpeta de cubos del servidor, después de su generación, a los servidores esclavos. El principio es que el servidor maestro generará los cubos en su carpeta local, luego la herramienta de sincronización copiará esta carpeta a todos los servidores esclavos. Todo ello fuera de los periodos de actividad del servidor. El maestro y los esclavos tendrán una vista idéntica de los cubos.
Otras configuraciones avanzadas
Cambiar la ruta de los archivos de datos
DigDash Enterprise almacena los datos de configuración, los modelos de datos, las carteras de información, los cubos, el historial de los flujos y varios otros archivos de trabajo en la carpeta del usuario del sistema operativa en un subdirectorio Application Data/Enterprise Server/<dominio>.
Por ejemplo, en Windows, este archivo es:
C:\Users\<usuario>\AppData\Roaming\Enterprise Server\ddenterpriseapi
Es importante modificar este archivo para garantizar la accesibilidad (derechos en lectura, escritura, ejecución) y para supervisar el espacio de almacenamiento.
Esta modificación es también interesante para razones de organización, de scripting, etc.
Para mas detalles, consulte la Guía de instalación de Windows o el Guía de instalación de Linux.
Configuración de LDAP (adswrapper): puerto y directorio de datos
Archivo modificado: digdash.properties
Consulte el capítulo Externalización de parámetros en un archivo digdash.properties para realizar esta manipulación.
El parámetro <nombre del archivo war >.ads.ldap.port (valor predeterminado: 11389) define el puerto de red utilizado por el servidor LDAP integrado en DigDash Enterprise.
Este valor debe cambiarse si ya lo está utilizando otro proceso en la máquina u otra instancia LDAP (de otro dominio DigDash en la misma máquina, por ejemplo).
Ejemplo: si la aplicación se llama adswrapper (adswrapper.war):
- adswrapper.ads.ldap.port = 11590
Para cambiar la ubicación para escribir datos en el directorio LDAP, consulte la Guía de instalación de Windows o el Guía de instalación de Linux.
Configuración avanzada del editor y de la consultación de cuadros de mandos
Archivo modificado: digdash.properties
Consulte el capítulo Externalización de parámetros en un archivo digdash.properties para realizar esta manipulación.
Propriedades disponibles:
- Nombre: SERVERURL
Valor: URL del servidor DigDash Enteprise
Descripción: URL del servidor al que se debe conectar en prioridad el cuadro de mando. - Nombre: DOMAIN
Valor: Nombre del dominio DigDash Enterprise
Descripción: Nombre del dominio al que debe conectarse en prioridad el cuadro de mando. - Nombre: FORCESERVERURL
Valor: booleano (por defecto: false)
Descripción: Se utiliza con el parámetro SERVERURL. Fuerza el servidor al que se conecta el tablero. El usuario no puede elegir otro servidor. - Nombre: FORCEDOMAIN
Valor: booleano (por defecto: false)
Descripción: Usado con el parámetro DOMAIN. Fuerza el dominio al que se conecta el panel. El usuario no puede elegir otro dominio. - Nombre: GRIDSIZEEDITOR
Valor: entero (por defecto: 10)
Descripción: Tamaño en píxeles de la cuadrícula magnética del editor de cuadros de mando. - Nombre: THEME
Valor: Nombre del tema (por defecto: vacío)
Descripción: Nombre del tema predeterminado utilizado para usuarios que no tienen un tema específico especificado.
- Nombre: urlLogout
Valor: URL
Descripción : Especifica una URL de salida a la que se redirige al usuario después de cerrar la sesión del cuadro de mando. Consulte el párrafo Redirección al desconectarse del cuadro de mando. - Nombre: CANCHANGEPASSWORD
Valor: booleano (por defecto: false)
Descripción: Permite la activación de un enlace "Contraseña perdida" en la página de inicio de sesión del cuadro de mando. Este enlace envía un código de restablecimiento por correo electrónico al usuario. Ver párrafo Activación de la función de restablecimiento de contraseña
Ejemplo de contenido parcial del archivo digdash.properties :
digdash_dashboard.FORCESERVERURL=true
digdash_dashboard.DOMAIN=ddenterpriseapi
digdash_dashboard.FORCEDOMAIN=true
digdash_dashboard.GRIDSIZEEDITOR=15
digdash_dashboard.THEME=Flat
digdash_dashboard.urlLogout=disconnected.html
digdash_dashboard.CANCHANGEPASSWORD=true
Redirección al desconectarse del cuadro de mando
Archivo modificado: digdash.properties
Puede especificar una URL que se mostrará en el navegador cuando el usuario cierre sesión en el panel.
Cambie el valor del parámetro urlLogout como en el siguiente ejemplo. De forma predeterminada, el valor está vacío, lo que significa un regreso a la página de autenticación del panel.
Se permiten URL relativas, desde la URL index.html de la aplicación digdash_dashboard:
Activación de la función de restablecimiento de contraseña
Archivo modificado: digdash.properties
Puede activar la función de restablecimiento de la contraseña perdida.
Esta función muestra un enlace "Contraseña olvidada" en la página de inicio de sesión del cuadro de mando que envía al usuario un correo electrónico que contiene un código de restablecimiento de contraseña.
Luego, el usuario es redirigido a una interfaz de reinicio para ingresar este código y una nueva contraseña.
Prerrequisito en el servidor DigDash :
- La funcionalidad también debe activarse a través de Configuración de servidores / Parámetros adicionales... / Varios / Habilitar el restablecimiento de contraseña
- Se debe configurar un servidor de correo electrónico válido en la página Configuración de servidores / Correo electrónico y SMS... / Servidor de correo
- Los usuarios deben tener una dirección de correo electrónico válida en el campo LDAP digdashMail
La función en el lado del tablero se activa pasando la variable CANCHANGEPASSWORD al valor true (ver capítulo Configuración avanzada del editor y de la consultación de cuadros de mandos)
Opcional: personalización del correo electrónico del código de restablecimiento
El asunto y el cuerpo del correo electrónico con el código de restablecimiento se pueden personalizar de la siguiente manera:
- Inicie el Web Studio
- Abre el gestor de traduccionnes: Gestor de diccionarios
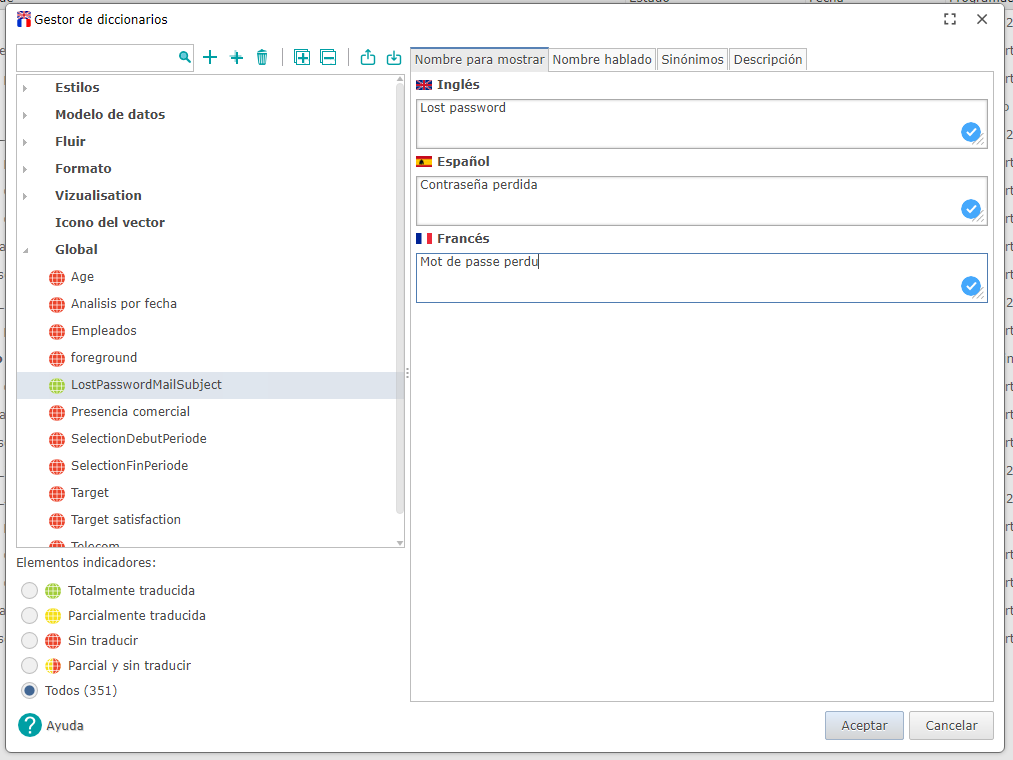
- Haga clic derecho en la categoria Global y haga clic en Agregar...
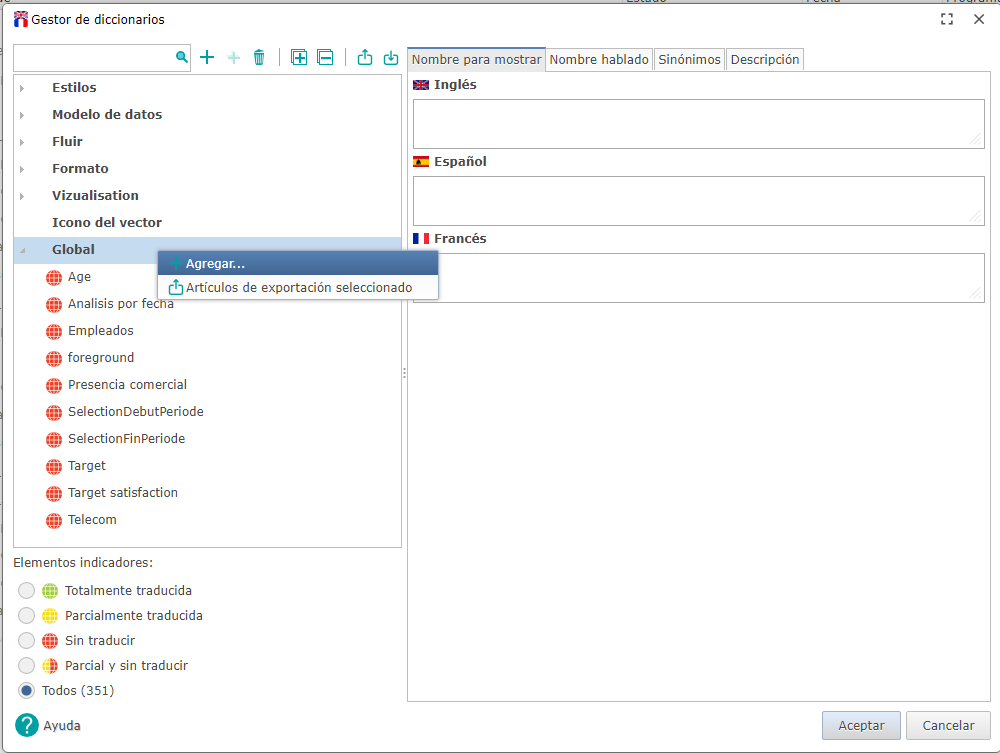
Nombre de la clave : LostPasswordMailSubject
- Saisir le sujet de l’émail dans les langues qui vous intéressent.
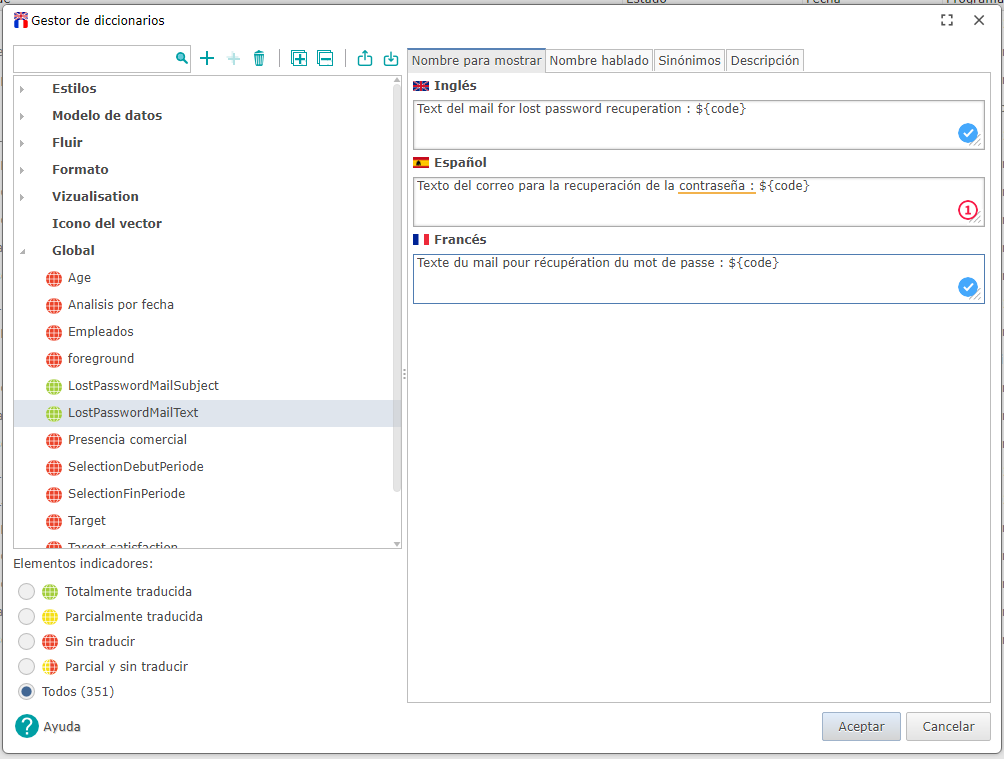
- De nuevo, Haga clic derecho en la categoria Global y haga clic en Agregar...
- Nombre de la clave : LostPasswordMailText
- Ingrese el cuerpo del correo electrónico en los idiomas que le interese. Tenga en cuenta que el cuerpo del correo electrónico debe contener al menos la palabra clave ${code}, que será reemplazada por el código de restablecimiento. Otra palabra clave disponible para sustitución es ${user}.
Configuración avanzada específica de la función de restablecimiento de contraseña
Archivo modificado: system.xml
Ejemplo de sintaxis XML:
Propriedades disponibles:
- Nombre: PROP_RESET_PASS_HASH
Valor: cadena de caracteres no vacía (por defecto: aléatoire)
Description : Especifica el código que se utilizará para generar el código de restablecimiento de contraseña. De forma predeterminada, esta cadena es aleatoria y se genera cuando se inicia el servidor. Puede especificar una cadena de caracteres que será utilizada por el algoritmo de generación de código de restablecimiento. Esto puede resultar útil si tiene varios servidores (equilibrio de carga HTTP) y si un código generado en un servidor se puede utilizar en otro. - Nombre: PROP_RESET_PASS_VALIDITY
Valor: entero positivo (por defecto: 1)
Description : Especifica el período mínimo de validez del código en incrementos de 10 minutos. Un valor de 1 da al código una validez entre 10 y 20 minutos, un valor de 2 entre 20 y 30 minutos, etc. La validez es importante para minimizar el riesgo de robo de códigos a posteriori. - Nombre: PROP_RESET_PASS_LENGTH
Valor: entero positivo (por defecto: 10)
Description : Especifica la longitud del código de reinicio. Un valor demasiado bajo está sujeto a intentos de ataques de fuerza bruta. Un valor demasiado grande está sujeto a errores de entrada del usuario.
Configuración de seguridad interna
Es posible configurar los mecanismos de protección integrados en DigDash. Puede consultar la manera de configurarlos en la página Configuración de seguridad avanzada.
Externalización de parámetros en un archivo digdash.properties
Todos los parámetros de la aplicación (archivos .war) de DigDash Enterprise son personalizables en un solo archivo de texto en formato properties.
El archivo digdash.properties se entrega a la raíz del directorio de instalación.
Todos los parámetros están presentes pero desactivados.
Para activarlos, elimine el carácter # al principio de la línea.
Los parámetros siempre van prefijados del nombre de la aplicación en cuestión (por ejemplo: ddenterpriseapi para los parámetros de la aplicación ddenterpriseapi.war).
Para que el archivo digdash.properties se tenga en cuenta con certeza, se debe especificar su ubicación al iniciar el servidor (Tomcat).
- En Windows con el servidor Tomcat previsto, no es necesaria ninguna intervención: el archivo setenv.bat ya está configurado para apuntar al archivo en la raíz de la instalación
- En Linux con el servidor Tomcat previsto, copie el archivo digdash.properties en la carpeta /etc/digdash
- Con su propio servidor Tomcat, deberá editar el archivo setenv.bat o setenv.sh para especificar la ubicación de su archivo digdash.properties.
Consulte la Guía de instalación de Windows o la Guía de instalación de Linux
Prioridad entre los niveles de configuración
Los parámetros se leen en el siguiente orden (tan pronto como se encuentra un valor, se ignoran los siguientes niveles):
- Parámetro en el comando de inicio del servidor Tomcat(-D<context>.<Parameter>=<value>)
- Archivo .properties especificado en la línea de comandos del servidor Tomcat (-D<context>.properties.path=/the/path/to/<context>.properties)
- Archivo .properties encontrado en la carpeta de trabajo del servidor Tomcat (<tomcat workdir>/<context>.properties)
- Parámetro global en la línea de comandos del servidor Tomcat (-D<Parameter>=<value>)
- Archivo web.xml para cada aplicación(<context>/WEB-INF/web.xml)
Especificar los parámetros de registro (logging) log4j.properties
Los parámetros de registro (o de logging) se definen en un archivo log4j.properties disponible en cada aplicación web implementada.
Varias opciones en la línea de comando de Tomcat han sido agregadas para permitir especificar archivos de configuración de registro (o de logging) externalizados:
-Ddigdash_dashboard.ddlog4j.properties.path="/path/to/log4j.properties"
-Dadswrapper.ddlog4j.properties.path="/path/to/log4j.properties"
También puede especificar la ubicación del archivo de registro (global) sin necesidad de especificar un archivo log4j.properties:
Configuración del Desktop Studio
El Desktop Studio de DigDash Enterprise también tiene algunos parámetros opcionales especificados en el archivo digdash.properties.
Consulte el capítulo Externalización de parámetros en un archivo digdash.properties para realizar esta manipulación.
Propriedades disponibles:
- Nombre: adminconsole.ddserver
Valor: URL del servidor DigDash Enterprise (por defecto: vacío)
Descripción: Especifica la URL del servidor al que se conectará Studio. Si no se especifica, Studio utilizará el servidor de URL del archivo JNLP. - Nombre: domain
Valor: Nombre de dominio DigDash Enterprise
Descripción: Especifica el nombre del dominio de DigDash Enterprise al que se conectará Studio. Si no se especifica, Studio utilizará el dominio especificado en la página de inicio de DigDash Enterprise.. - Nombre: forceServerDomain
Valor: booleano (por defecto: false)
Descripción:Indica al Studio que la URL del servidor y el dominio son editables (false) o no (true) a través del botón Avanzado en la ventana de inicio de sesión de Studio. Si este parámetro está habilitado, le recomendamos que especifique los parámetros de ddserver y domain. - Nombre: dashboard
Valor: Nombre de la aplicación del cuadro de mando
Descripción: Le permite especificar el nombre de la aplicación del cuadro de mando. Si no se especifica, Studio utilizará el nombre de la aplicación especificado en la página de inicio de DigDash Enterprise, por ejemplo, "digdash_dashboard". - Nombre: authMode
Valor: Modo de autenticación del Studio (por defecto: « default ») : default, NTUser, NTUserOrLDAP, o "NTUserOrLDAP,loginForm"
Descripción: Modo de autenticación específico de Studio. El servidor de DigDash Enterprise debe reflejar un modo de autenticación compatible (variable authMethod en la configuración del servidor): consulte la documentación para conocer los complementos relacionados con la autenticación y SSO. Los valores posibles son : « default », « NTUser », « NTUserOrLDAP » et « NTUserOrLDAP,loginForm ». - Nombre: sslNoPathCheck
Valor: booleano (por defecto: false)
Descripción: Se utiliza como parte de una conexión HTTPS. Indica a Studio que no verifique la ruta de certificación del certificado de seguridad. Se utiliza para probar una configuración SSL con un certificado autofirmado. Esta configuración no se recomienda en producción. - Nombre: sslNoHostNameCheck
Valor: booleano (por defecto: false)
Descripción: Se utiliza como parte de una conexión HTTPS. Indica a Studio que no verifique el nombre de dominio de Internet. Se utiliza para probar una configuración SSL con un certificado autofirmado. Esta configuración no se recomienda en producción.
- Nom : maxHeapSize
Valor: Cantidad de memoria (por defecto: dependiendo de la JVM de la estación de trabajo cliente)
Descripción: Especifica la cantidad de memoria del nodo cliente asignada a Studio. La sintaxis es <cantidad><unidad>, donde la unidad es una letra "m" (megabytes) o "g" (gigabytes). Ejemplo: maxHeapSize = 2048m
Directorios de datos DigDash Enterprise
DigDash Enterprise almacena datos en diferentes carpetas. Este capítulo resume estos archivos.
Datos de configuración
Ubicación (por defecto) : Directorio « Application Data » del usuario que inicia Tomcat(Windows), o carpeta del usuario (linux).
Contenido: Subcarpetas que contienen modelos de datos, cuadros de mando, carteras de flujo, formatos, fórmulas, scripts, estilos, cadenas de conexión, etc. :
- config : datos de configuración comunes, datos de configuración de roles, copias de seguridad y carpetas web personalizadas
- datasources : archivos de servidor de documentos predeterminados
- server : datos de configuración del usuario: cartera, modelo y paneles de datos personales, y servidor de documentos personalizado
Modificación: digdash.properties, ver la parte Cambiar la ruta de los archivos de datos.
Datos generados
Ubicación: Subcarpetas cubes y history del directorio de datos de configuración.
Contenido: Cubos, historial de flujos :
- cubes : subcarpeta de los cubos generados (uno por modelo de datos)..
- history : historial de todos los flujos, archivos javascript generados (modelo de datos, vistas de flujo).
Modificación: Imposible directamente. Debe cambiar la ubicación de la carpeta principal (Datos de configuración) o crear vínculos.
Datos LDAP
Ubicación (por defecto) : carpeta ldapdigdash en el directorio de trabajo de Tomcat (« workdir »).
Contenido: Archivos de la partición LDAP que contienen definiciones de los usuarios, de los roles y de los derechos DigDash
Modificación: digdash.properties, ver la parte Configuración de LDAP (adswrapper): puerto y directorio de datos.
Base de datos DDAudit
Ubicación (por defecto) : directorio de trabajo de Tomcat (« workdir »).
Contenido: Archivo de base de datos (H2) que contiene las tablas de datosDDAudit.
Modificación: digdash.properties (Ver también Despliegue del modulo de Audit)
Archivos de registo (log)
Ubicación (por defecto) : Archivo de registro (log) de los módulos de DigDash Enterprise (ddenterpriseapi, digdash_dashboard, studio, adswrapper).
El nombre es ddenterpriseapi.log por defecto.
Contenido: registro applicativo
Modificación: log4j.properties (todas las webapps)