Connecteur Elasticsearch
Modifié par jhurst le 2022/11/14 09:18
Prérequis
- Un serveur Elasticsearch
- DigDash 2020R1 ou au dessus
Création d'une source de données Elasticsearch
Création d'une connexion nommée (optionnel)
Vous pouvez créer une connexion nommée afin de pouvoir réutiliser cette connexion dans plusieurs sources de données différentes. En centralisant la configuration de votre connexion, vous pourrez plus facilement reconfigurer la connexion sans devoir modifier les sources de données dans l'avenir si besoin.
Pour créer cette connexion nommée :
- Ouvrez l'interface de gestion des connexions aux bases de données.
- Cliquez sur le bouton ajouter.
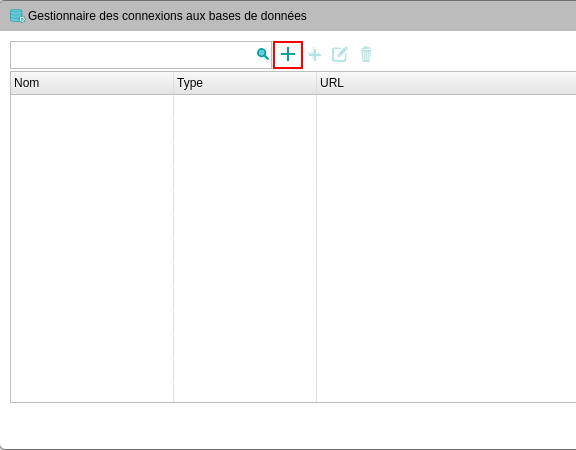
- Choisissez le type ES, remplissez la configuration en utilisant les boutons d'aide pour plus d'informations concernant les champs, puis cliquez sur OK.
Configuration de la source de données
- Sélectionnez la source de données de type Elasticsearch (ES) dans la liste des sources de données du studio.
- Sélectionnez la connexion nommée, ou configurez une connexion manuelle pour la source de données.
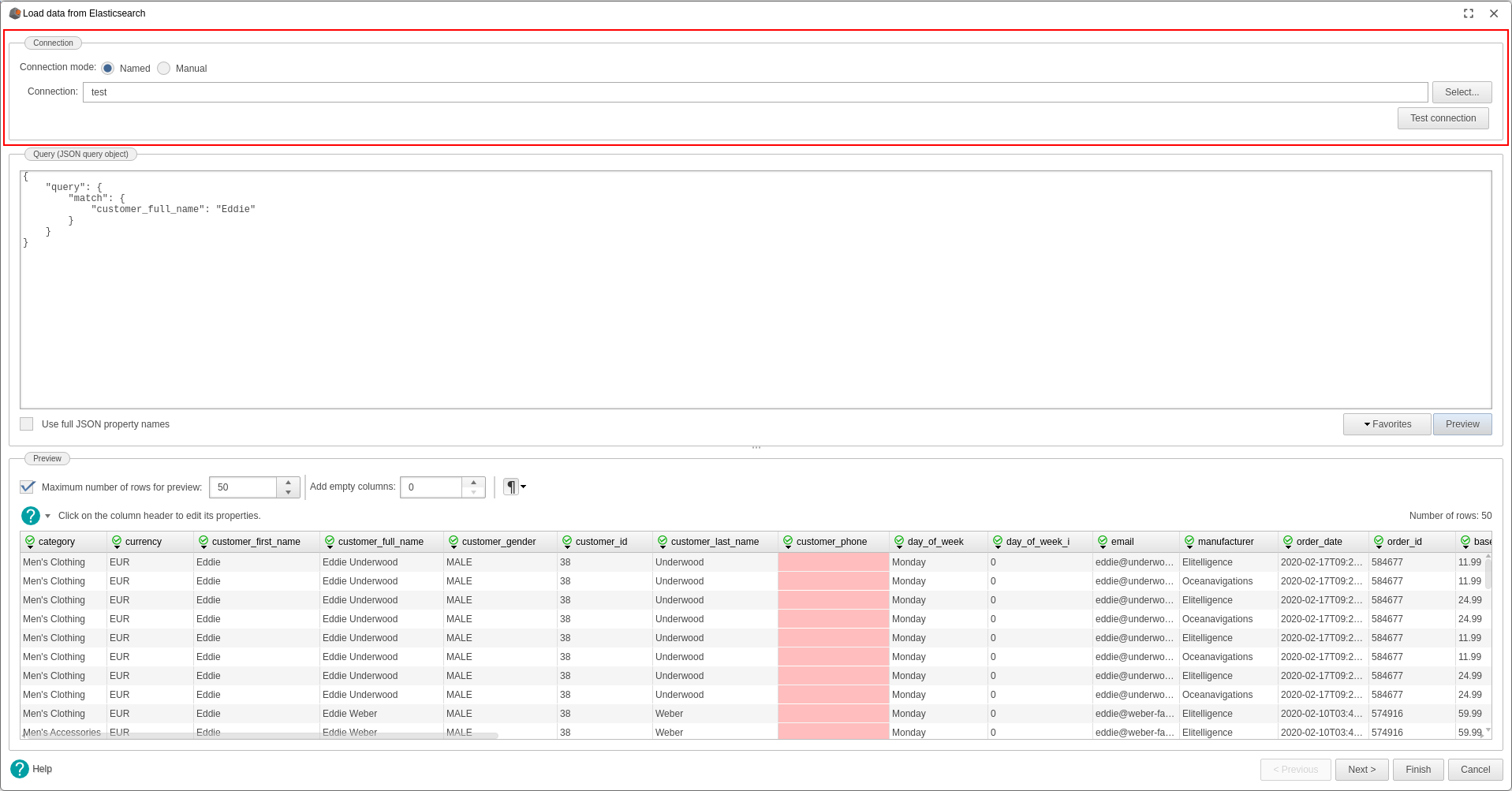
- Configurez la requête à exécuter. Les requêtes doivent être du type Request Body Search (https://www.elastic.co/guide/en/elasticsearch/reference/current/search-search.html).
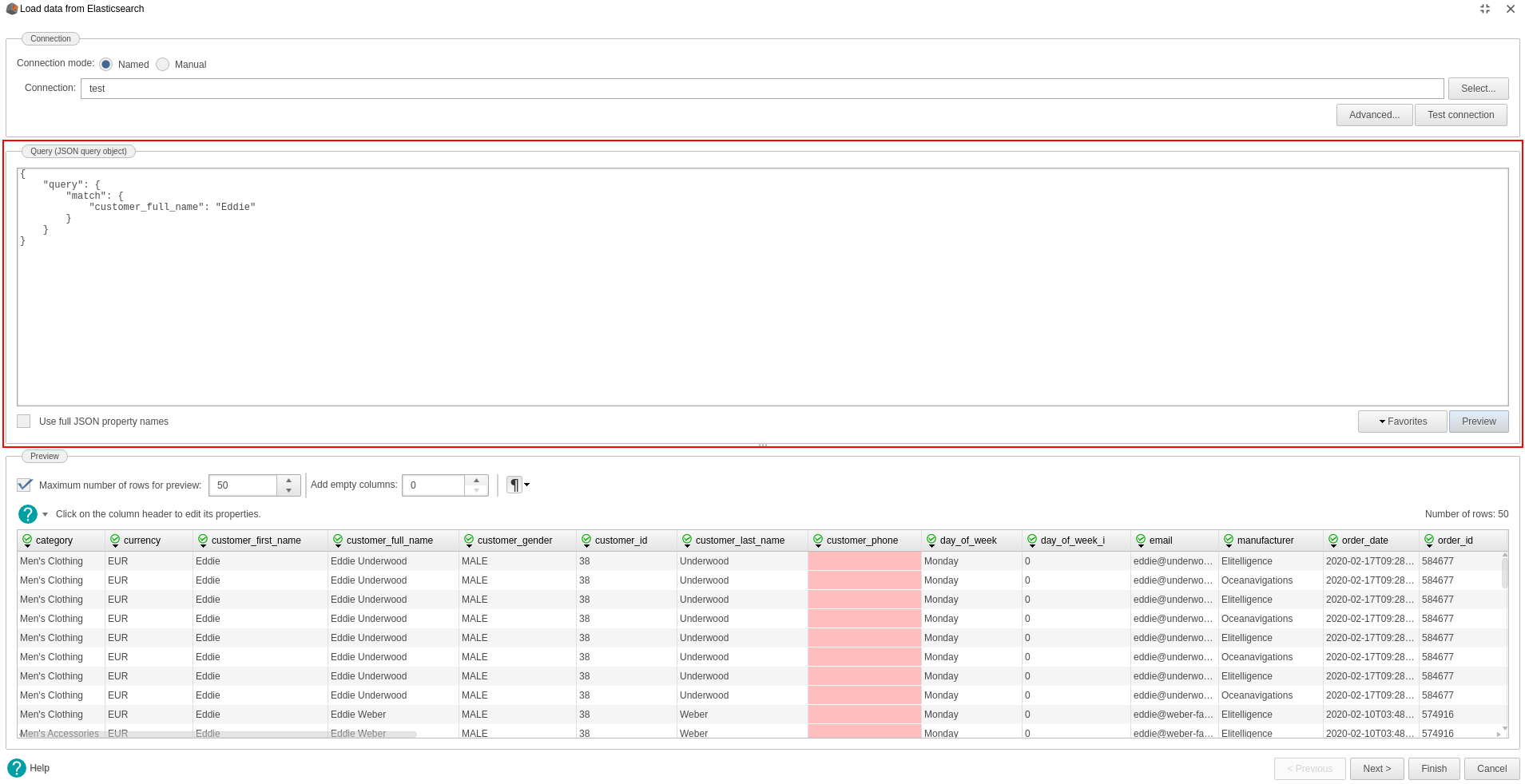
- Vérifiez vos données dans la partie Prévisualisation.
- Cliquez sur Suivant puis complétez la configuration de la source en spécifiant un nom et en configurant les options additionnelles communes à toutes les sources de données DigDash.
Configuration du mode incrémental
La source de données Elasticsearch supporte un mode incrémental permettant de minimiser les requêtes vers la base de données.
- Cliquer sur Avancé... dans la boite de configuration de la source de données.
- Cocher la case Mode données incrémentales.
- Un message d'avertissement vous informe que :
- Le mode incrémental utilise une colonne de référence qui identifie chaque enregistrement du résultat de manière unique (par exemple un auto-increment, un identifiant, une date...)
- Le requête doit être triée sur cette colonne de référence (et contenir cette colonne)
- La requête doit contenir une clause range sur cette colonne comparant sa valeur à une variable ${LASTVAL}. Exemple : "query": { "range" : { "order_date" : { "gt" : "${LASTVAL}" } } }
- Le mode incrémental a été prévu pour traiter incrémentalement des grand volume de données, et n'est pas optimal pour de faibles volumes.
- Si la requête est modifiée à l'avenir, l'historique précédemment accumulé dans le cube sera invalidé. ${LASTVAL} sera évalué à 0 et, selon la clause range spécifiée, l'intégralité des données sera rapatriée de la base de données.
- Saisir le nom de la colonne qui sera utilisée comme référence incrémentale dans le champ Colonne de référence
- Ajouter une clause range à votre requête SQL (ou une condition AND sur une clause WHERE existante) qui teste si la colonne de référence est supérieure à "${LASTVAL}". La syntaxe exacte peut dépendre de votre base de données et du type de la colonne. La comparaison est faite de manière lexicographique, il est préférable donc que la comparaison soit faite via une chaîne de caractère.