
Securing a data model
This guide describes the methods for securing the information contained in data cubes. This is generally referred to as Row Level Security. We also refer to this as 'personalisation' of cubes and flows.
It presents an overview of classic personalisation methods with the use of user variables, and then introduces a more powerful and flexible approach: Live Security, dynamic customisation based on scripts.
💡 See Live Security: examples of use for detailed usage examples.
Security via personalisation
Row-level security can be achieved by personalising cubes or flows using user variables (${user.<variablename>}).
Personalisation at data model (cube) level
Line-level security is resolved at data cube generation via the use of user variables (${user.<namevariable>}) in the definition of the data source and data model. For example in SQL: SELECT * FROM UneTable WHERE country='${user.country}' AND service in '${user.services}'.
In this example, each user has a country variable equal to their country, and a services variable which is a comma-separated list of department names (Marketing,Sales,Logistics) to which the user has access rights.
Thus, for each user, DigDash generates a different cube (one for each combination of variable values) containing only the data corresponding to each user's "personalisation profile". If several users have the same values for these variables, they are said to have the same profile, so they share the same cube.
This mechanism is very simple to set up, and generally makes it possible to segment the volume of data, and therefore the memory load on the server during consultation. Users rarely all connect to the server at the same time, so the server will not need to store all the cubes in memory at all times.
Another advantage is that, depending on the type of data source, the security rule can be very advanced. Our simple example of filtering on two columns, countries and services, can take into account other criteria, come from other tables (that we don't want to include in the cube), etc.
On the other hand, this mechanism multiplies the number of cubes to be generated and therefore the number of queries to the data source.
Finally, the security rule can generate data redundancy between different cubes, representing the common part of the data that several users can see, even if they don't share exactly the same profile. This common part is duplicated in several cubes.
- Advantages : Strong security, easy to implement, great flexibility (the complexity of security depends on the capabilities of the data source).
- Disadvantages : More queries to generate cubes, risk of data redundancy in several cubes.

Personalisation at flow level (chart/table)
Another more dynamic approach is to use these user variables in the value of filters on each chart using the cube. To take the previous example, the cube takes its data from an SQL source: SELECT * FROM ATable. It is unique (not personalised) for all users, and therefore large. In all the flows using this cube, you can add a filter on the dimension Country ( rule "equals to" ${user.country}) and on the dimension Department ( rule "equals to" rule ${user.services}). Each time a flow is displayed, the filter will be applied to the data cube so that only the rows to which the user has access are retained. Of course, browsing these dimensions must be forbidden to the user so that they are restricted to this perimeter.
The advantage is that there is only one cube to generate, and therefore only one request to the data source.
On the other hand, as the filtering is controlled by the flows themselves when the dashboards are consulted, there is a risk of allowing users to access data that does not concern them. This can happen either because of a design flaw in the dashboard pages (e.g. the prohibition on navigation on a dimension has been omitted), or through manipulation (by an expert user) of the display requests sent to the server.
Finally, another disadvantage is the reduced flexibility of the security rule. In this approach, it depends directly on what has been stored in the cube and relies solely on dimension filtering.
- Advantage : A single request for the generation of a single cube.
- Disadvantages : tedious to implement (pre-configure filtering on all flows), low security, limited security rules.

Comparison of the 2 types of personalisation
Here is a table comparing these two personalisation approaches:
| Cube personalisation | Flow personalisation | |
| Security | High | Low |
| Generation of cubes | X cubes generated (1 per "personalisation profile") => X queries | 1 cube generated => 1 single query |
| Implementation | Simple | Tedious |
| Flexibility | Depends on the data source (e.g. SQL) | Filtering on cube data only |
Security via Live Security
Concept
The Live Security approach aims to retain only the advantages of the two personalisation mechanisms described above: strong security, a low number of queries required to generate the cube, and implementation that is as simple as possible while retaining a sufficiently high level of flexibility.
It allows security rules to be added at the level of the data model itself, without multiplying the number of cubes generated and without having to manage security at row level in the flows.
Security is expressed through simple filtering rules set up using a wizard to cover the most common requirements for restricting browsing to members of one or more dimensions, depending on a user's variables.
For advanced needs, you can use a Javascript script that will be executed each time the cube is queried on the incoming selection. In this case, the selection can be transformed. This can range from simple filtering similar to the "Flow personalisation" approach to more complex transformation based on the user's profile. For example, changing an exploration level, deleting an axis, one or more measures, etc.
Some examples of advanced selection transformations (advanced examples of Live Security are detailed in our knowledge base):
- Filtering one dimension or another according to the value of a user variable.
- Creating "OR" filter rules between dimensions.
- Query another cube to extract a dynamic security perimeter, depending on the current selection...
On the security side, this transformation, whether simple or advanced, is applied before the selection is processed on the server side and only depends on the user's profile. There is no way for a user, even an expert, to alter this process in the same way as for flow personalisation.
- Advantages : A single request for the generation of a single cube, strong security, great flexibility (potentially total transformation of the flow selection).
- Disadvantages : Potentially complicated implementation (Javascript) for complex requirements. But there is an interface that helps users to create simple Live Security filters, without Javascript.

Comparison of security methods
Here is a table comparing this new approach with the two previous personalisation approaches:
| Cube personnalisation | Flow personalisation | "Live Security" | |
| Security | Strong | Low | High |
| Generation of cubes | X cubes generated (1 per "personalisation profile") => X queries | 1 cube generated => 1 single request | 1 cube generated => 1 single query |
| How to set it up | Simple | Tedious (per Flow) | Assistant / Script |
| Flexibility | Depending on the data source (e.g. SQL) | Filtering on cube data only | Selection transformation |
Implementation
We will now look at how to implement the Live Security mechanism using a standard dimension filtering example.
The example is based on a data source containing at least two columns Area (level country) and department and value columns (measures). Each user is assigned to a country and one or more department and will therefore only see the figures relating to them. Some users may have the right to see all countries and/or all services.
Requirements
Users
Each user has two user variables in LDAP: country and department, which define the user's security perimeter. Each of the two variables can be empty, which means that the user can view all countries and/or departments. The variable department can be a list of service names separated by commas (no spaces after the commas).
For example, we have the following 2 users:
- User U1 :
- country ='fr'
- department = 'Marketing,Sales'
- User U2 :
- country = 'de'
- department = (empty string)
Data model
The data model is based on an SQL source on which the following query is executed:
Note that there is no WHERE clause in this query, as the aim is to generate a single cube containing all the data for all the users.
The data model therefore contains two dimensions and two measures.
Creation of the Live Security function
Live Security is activated in the Advanced configuration screen of the data model, on the Advanced tab. Here we describe the two ways of developing a Live Security function, either via our assistant dedicated to simple functions, or via the creation of a Javascript function.
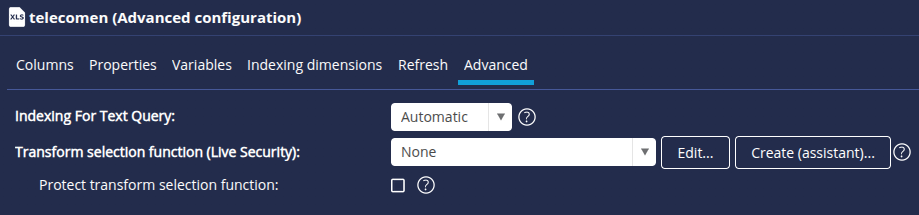
- To create a simple Live Security function without Javascript, you can click on the Create (assistant)... button next to the Transformation selection function drop-down list.
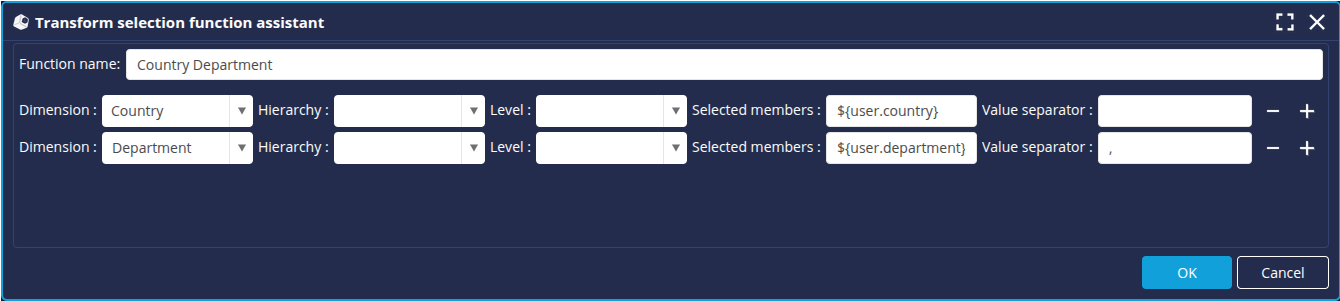
- Enter a name for the function.
- Choose the dimension Country for the first filter rule. This rule has no hierarchy or level, so leave these two fields empty.
- Enter ${user.country} in the Selected members field.
- Add a new rule by clicking on the + icon
- Select the dimension Department on the second filter rule. This rule has no hierarchy or level, so leave these two fields empty.
- Enter ${user.department} in the selected members field.
- As we have defined that the user variable department can have multiple values separated by commas, a comma (,) must be entered in the value separator field.
- Click OK to create the new Live Security function.
Creating a function based on a script
- To create an advanced Live Security function based on a JavaScript script, click the Edit... button next to the Transformation selection function drop-down list.
- Choose Shared function in the Function type.
- Add a new pre-defined function by clicking on the + button in the Function Manager toolbar.
- Enter a name for the function.
You can now enter a script to transform the selections made on the cube corresponding to this data model. This is described in the following paragraph.
The script to be written is the body of a JavaScript function which takes a "selection" object as its parameter. This object represents the description of the result we want to obtain from the cube ("flattening" operation). This complex object defines the desired axes, dimensions, filters, measurements and other parameters specific to each type of flow (chart, table, etc.). What interests us in this example are the dimension filter parameters. The aim is to transform this selection to include two 'forced' filters, one on the user's country and one on their departments, if the user has defined (non-empty) variables for country and/or departments.
Let's start by retrieving the value of the user's variable countryusing the function getUserAttribute('<variableName>') :
Then, if the country variable is defined and not empty, we apply a filter to the selection object:
if (country != null && country != '')
{
var tabCountry = [country]; //creation of a table containing the country
var dim = selection.dm.getDimensionById('Country');
var filt = new FilterSelection(dim, -1, -1, [], tabCountry);
selection.setFilter(filt);
}
Explanation: The filter is constructed using the instruction new FilterSelection(Dimension, hierarchyIndex, levelIndex, [ ], arrayMembers):
- Dimension: The dimension object can be retrieved directly from the data model accessible via selection.dm, using the getDimensionById(dimId) function.
- hierarchyIndex and levelIndex: Then, in this example, we filter the root members of the dimension directly, there is no hierarchy or level to specify (...-1, -1...).
- [ ] (empty array): Used internally, do not modify.
- arrayMembers: Finally, a filter on a dimension can have several members selected, so an array of members must be passed to it (here tabCountry). For the country, as the user only has one, the array contains only one element.
Then we apply this filter to the selection using selection.setFilter(...).
Finally, we do the same thing for the variable department, which represents a list of departments, which we treat specifically using the Javascript split() function. This splits a character string into an array of character strings according to a separator character (the comma in our case):
var department = getUserAttribute('department');
if (department != null && department != '')
{
var tabDepartment = department.split(',');
var dim = selection.dm.getDimensionById('Department');
var filt = new FilterSelection(dim, -1, -1, [], tabDepartment);
selection.setFilter(filt);
}
Use
All that remains is to create a flow based on this data model and place it on a dashboard page.
If you don't hide the dimensions country and department in the dashboard (or in the flow) it will still be possible to filter on one of these dimensions. However, the filter will be overwritten by the Live Security script if the user has a non-empty value for his variable country or department. In the end, filtering on these dimensions in the dashboard is only useful for users who have the right to see everything, i.e. those who have an empty value in their variable country and/or department.
API reference
There are a few recommended methods for manipulating a selection, presented below.
- Retrieving user information
Description : Returns the LDAP attr attribute of the user. See the User attributes page for a list of default user attributes.
It is also possible to retrieve the value of user parameters. See the paragraph Adding user parameters paragraph for more information.
Example:
- Retrieving user session information
Description: Returns the user's Session attr attribute for the current session.
Example:
- Retrieving information from the current selection or data model
Description: Returns the value of the corresponding model variable (DDVar). These variables are defined in the data model and correspond to a widget in the dashboard page.
Example:
(Dimension) selection.dm.getDimensionById(dimId)
Description: Returns a Javascript object corresponding to the dimId identifier dimension. Returns null if this dimension is not in the current model. This object is needed for other functions, for example to build a filter.
Example:
- Selection transformations
FilterSelection function
// dim : dimension to be filtered
// hierarchy : hierarchy index (or -1 if no hierarchy)
// level : hierarchy level (or -1 for root)
// [] : internal array — always empty, do not touch!
// ValuesTab : List of values/members to be filtered
Description: Returns a JavaScript object corresponding to the desired filter on the dimension in parameter, in a given hierarchy and level (-1 if no hierarchy/level) and with the specified members. This object is needed for other functions, for example to apply the filter to the selection.
Example :
void selection.setFilter(filter)
Description: Applies a filter to the current selection. Overwrites the existing filter on this dimension if there was one.
Example: Description
void setDDVar(variable, value)
Description: Modifies the value of a model variable (DDVar) for the current selection. The value of the variable is not modified persistently, only for this selection.
Example:
FilterSelectionMatch function
// dim : dimension to be filtered
// hierarchy : hierarchy index (or -1 if no hierarchy)
// level : hierarchy level (or -1 for root)
// values : table of values to be filtered
// operators : table of operators applied to each value
// matchMode : 0 = all rules must be true (AND), 1 = at least one of the rules must be true (OR)
Description: Allows you to filter a dimension using one or more conditions, specifying which operator to use for each value (equal, begins with, contains, etc.).
values and operators are parallel arrays: each value has its own operator.
It is also possible to choose whether the conditions should be combined using AND or OR.
The following operators are available:
| JavaScript code | Value | Meaning |
|---|---|---|
| OP_ISNOTNULL | 0 | Is non-null |
| OP_ISNULL | 1 | Is null |
| OP_EQUAL | 2 | Equals |
| OP_CONTAIN | 3 | Contains |
| OP_NOTCONTAIN | 4 | Does not contain |
| OP_NOTEQUAL | 5 | Different |
| OP_MATCHREGEXP | 6 | Matches the regular expression |
| OP_CONTAINWORD | 7 | Contains the word |
| OP_NOTCONTAINWORD | 8 | Does not contain the word |
| OP_SUP | 9 | Greater than |
| OP_INF | 10 | Lower |
| OP_SUPEQUAL | 11 | Greater than or equal to |
| OP_INFEQUAL | 12 | Less than or equal to |
| OP_STARTSWITH | 13 | Starts with |
| OP_ENDSWITH | 14 | Ends with |
| OP_ISIN | 15 | Is in |
| OP_ISNOTIN | 16 | Not in |
Example with 1 single filter :
In this case :
- Value: ['admin']
- Operator: [13] → OP_STARTSWITH → login must begin with admin
- matchMode: 0 → only one rule, so AND or OR changes nothing.
Example with 2 filters:
In this case:
- We combine 2 rules:
- login starts with admin (13 = STARTSWITH)
- login equal to John (2 = EQUAL)
- matchMode: 1 → at least one of the rules must be true (OR logic).