Définir les paramètres avancés du cube
L'onglet Avancé permet de définir les paramètres avancés du cube.
Ce onglet est réservé à des cas spécifiques, par exemple, pour de gros cubes, longs à charger ou des besoins particuliers en termes de rafraîchissement de données.
Paramétrer l'indexation
Indexer les modèles de données permet d'utiliser les données du modèle (mesures, dimensions) dans les requêtes en langage naturel. Consultez la page Requête en langage naturel pour plus d'informations.
Trois options sont disponibles :
- Automatique (valeur par défaut) : seuls les modèles utilisés par au moins un flux sont indexés pour les requêtes en langage naturel. Les modèles qui ne sont pas utilisés directement par un flux ne sont pas indexés (modèles intermédiaires servant à la construction d'autres modèles par exemple).
- Toujours : le modèle est toujours indexé pour les requêtes en langage naturel même s'il n'est pas utilisé directement par un flux.
- Jamais : le modèle n'est jamais indexé pour les requêtes en langage naturel.
Définir la fonction de transformation de sélection
La fonctionnalité Live Security est un moyen de sécurisation des informations contenues dans les cubes de données. Nous appelons aussi cela la « personnalisation » des cubes et des flux. Elle permet d’ajouter des règles de sécurisation au niveau du modèle de données lui-même.
La sécurisation est exprimée au travers d'une fonction de transformation de sélection.
Dans le cas de règles de filtrage simple, vous pouvez créer une fonction via l'assistant en cliquant sur le bouton Créer (assistant).
Pour des besoins avancés, vous pouvez utiliser une fonction Javascript : sélectionnez l'exemple de sécurisation dynamique des données dans la liste déroulante puis cliquez sur Éditer pour créer une fonction.
Cochez la case Protéger la fonction de transformation de sélection pour empêcher sa modification dans les modèles dépendants.
Consultez la page Live Security pour des instructions détaillées.
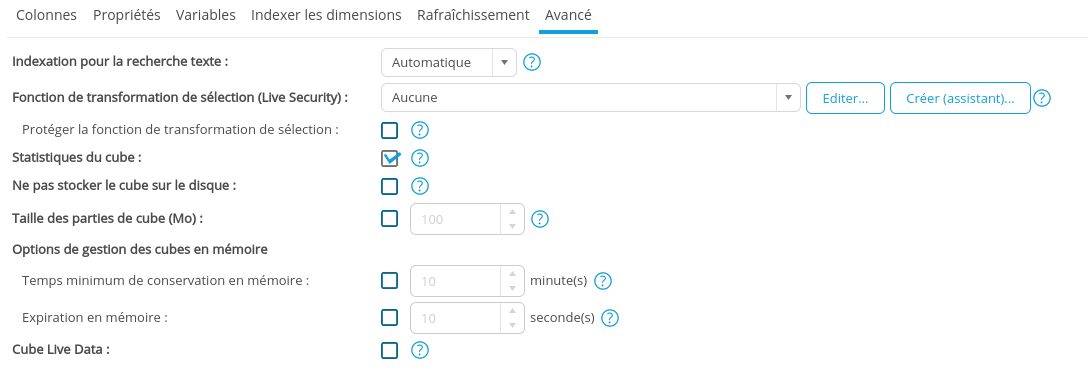
Autres options
| Statistiques du cube | Cochez pour activer les statistiques du cube : aberrations, anomalies, statistiques des mesures, etc. Pour accéder au rapport de statistiques, dans le panneau de gestion des modèles de données, cliquez-droit sur le modèle puis Statistiques du cube. Consultez la page Afficher les statistiques du cube pour plus de détails. |
|---|---|
| Ne pas stocker de cube sur le disque | Cochez la case si vous souhaitez que le cube soit stocké uniquement sur la mémoire du serveur. |
| Taille des parties du cube (Mo) | Les données du cube sont découpées en parties. Cochez la case si vous souhaitez modifier la taille utile de chaque partie. Elle est définie à 100 Mo par défaut. Cette option est principalement utilisée dans le cas de d'utilisation de plusieurs serveurs en mode Cluster. Consultez la page Réglages avancés des paramètres système pour plus de détails. |
| Temps minimum de conservation en mémoire | Ce paramètre définit un délai avant la suppression du cube de la mémoire du serveur après sa dernière utilisation. Si vous utilisez le cube pendant la période du délai, celui-ci sera étendu d'autant. Il est défini à 10 minutes par défaut. |
| Expiration en mémoire | Cochez la case pour définir un délai avant la suppression du cube de la mémoire après son chargement ou sa création. Utiliser le cube pendant la période du délai ne le modifiera pas. |
| Cube Live Data | Si la case est cochée, chaque utilisation du cube (par exemple, filtrage) réinterroge la source de données. |