Utilisation de plusieurs serveurs en mode "Cluster"
- Installer DigDash Enterprise en mode "Cluster"
- Configurer le cluster
- Utilisation de plusieurs maîtres dans un cluster
- Paramètres avancés spécifiques au clusters
- Utiliser le cluster
Pour gérer un plus grand volume de données (milliard de lignes), il est possible d'utiliser plusieurs serveurs en mode "Cluster". Chaque serveur devient un nœud de calcul du cluster.
Ce dernier regroupe un serveur maître et des serveurs esclaves.
Le serveur maître s'occupe de gérer les modèles, les documents, les rôles, les utilisateurs, les sessions et de générer les cubes et les flux (rafraîchissement). A l'identique d'un serveur Digdash Enterprise en mode standard mono-machine.
Les serveurs esclaves additionnels ne sont utilisés que pour aider à l’aplatissement interactif des cubes de données volumineux, lors de l'affichage de flux, filtrage, drills, etc.
Il existe deux architectures de clustering dans DigDash Enterprise :
- Clustering interne : Décrit dans ce chapitre
- Cluster Apache Ignite : Module Cluster Apache Ignite
Installer DigDash Enterprise en mode "Cluster"
Pré-requis: plusieurs machines connectées entre elles par le réseau
Serveur maître (sur la machine la plus puissante du cluster)
- Installation standard de DigDash Enterprise (voir ).
- Démarrer le serveur normalement avec start_servers.bat
Serveur esclave (sur chacune des autres machines du cluster)
- Installation standard de DigDash Enterprise (voir Guide d'installation Windows ou Guide d'installation Linux).
La différence est qu'un serveur esclave n'a pas besoin de licence pour servir d'unité de calcul au cluster, ni d'annuaire LDAP, ni de l'application digdash_dasboard dont le war peut être supprimé de Tomcat. - Démarrer uniquement le module Tomcat, avec start_tomcat.bat ou apache_tomcat/bin/startup.sh
Configurer le cluster
Pour configurer le cluster, répétez la procédure suivante sur chaque serveur du cluster :
- Avec un navigateur, connectez-vous à la page principale de DigDash Enterprise (ex: http://<serveur>:8080).
- Cliquez sur Configuration, puis Paramètres Serveur.
- Identifiez-vous en tant qu'administrateur de DigDash Enterprise (admin/admin par défaut) pour afficher la page des paramètres du serveur.
- Allez dans le menu Serveurs -> Paramètres du cluster.
- Remplissez les différents champs en fonction de chaque machine serveur (voir explications ci-dessous).
Section Performance du système

La section Performance du système définit les capacités de la machine courante dans le cluster. Les paramètres Nombre de CPU, Score CPU et Mémoire allouée permettent de répartir au mieux la charge de calcul.
- Nombre de CPU : le nombre de processeurs * nombre de cœurs sur chaque processeurs. Potentiellement multiplié par un facteur si les processeurs bénéficient d'une technologie type Hyper-threading. Par défaut -1, s'appuie sur les données renvoyées par le système d'exploitation
- Score CPU : c'est une note entre 1 et 10 qui permet de relativiser la performance d'un noeud du cluster par rapport aux autres (cas d'un cluster hétérogène). Par défaut, -1 donne une note moyenne (5).
- Mémoire allouée : la fraction de la mémoire maximale autorisée dans le cadre d'utilisation du serveur comme unité de calcul. Cette valeur est inférieure ou égale à la mémoire allouée au serveur Tomcat. Par défaut, -1 autorise toute la mémoire.
Section Clusters autorisés
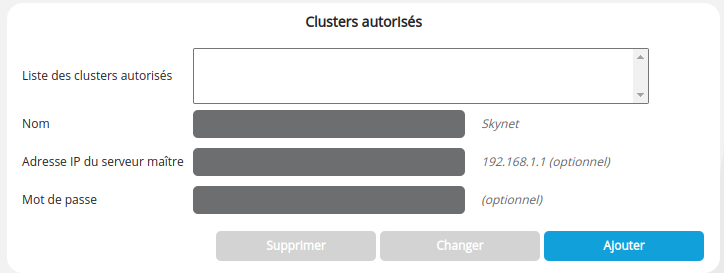
La section Clusters autorisés permet de spécifier si la machine courante peut être utilisée comme esclave d'un ou plusieurs cluster(s), et si oui lesquels. En effet une machine peut servir à plusieurs clusters DigDash Enterprise. Cette section restreint cette utilisation en tant qu'esclave à seulement certains clusters (liste Sélection).
C'est également dans cette section que nous définissons le Mot de passe du serveur courante dans le cluster sélectionné. Sans mot de passe le serveur ne peut être esclave dans ce cluster.
Pour ajouter un cluster autorisé à utiliser ce serveur esclave:
- Renseignez les champs suivants :
- Nom : nom du cluster (arbitraire)
- Adresse IP du serveur maître : adresse IP du serveur maître du cluster autorisé à utiliser ce serveur comme esclave (ex: http://192.168.1.1)
- Mot de passe : Mot de passe de l'esclave dans le contexte du cluster sélectionné
- Cliquez sur le bouton Ajouter pour ajouter ce cluster à la liste des clusters autorisés
Section Définition du cluster
À renseigner seulement sur le serveur Maître du cluster.
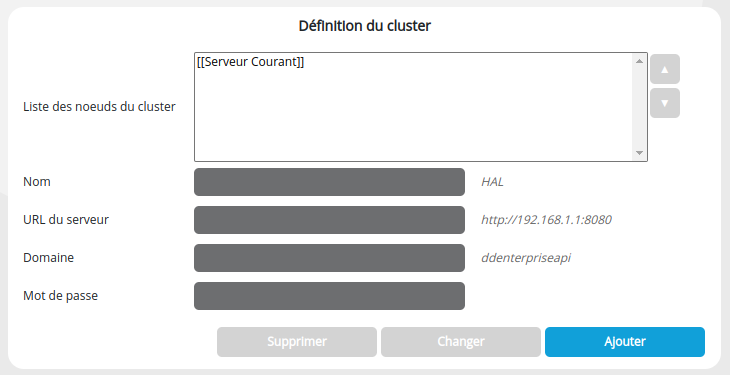
La section Définition du cluster ne concerne que le serveur maître du cluster. C'est ici que nous créons un cluster en listant les serveurs esclaves du cluster ainsi que le maître lui-même (liste Sélection, champs Nom, Adresse, Domaine et Mot de passe). Le serveur maître est implicitement le serveur via lequel vous vous êtes connecté à cette page.
Pour ajouter une machine esclave au cluster:
- Renseignez les champs suivants :
- Nom : nom de machine esclave (arbitraire)
- URL du serveur : URL du serveur esclave (ex: http://192.168.1.123:8080)
- Domaine : Domaine DigDash Enterprise (par défaut ddenterpriseapi)
- Mot de passe : Mot de passe de l'esclave tel que vous l'avez précédemment tapé lors de la configuration de la machine esclave (section Clusters autorisés, champ Mot de passe)
- Cliquez sur le bouton Ajouter pour ajouter cette machine à votre cluster.
Utilisation de plusieurs maîtres dans un cluster
Certain déploiements nécessitent l’utilisation de plusieurs serveurs maîtres au sein d’un même « cluster ». Par exemple dans le cas d’un load balancer HTTP en amont qui envoie les sessions utilisateurs sur l’une ou l’autre machine maître. Ce mode est supporté dans DigDash en définissant plusieurs clusters identiques (un par machine maître). La liste des machines (Section Définition du cluster) doit être strictement identique sur toutes les définitions des clusters. C’est pour cela qu’il est possible de changer l’ordre des machines dans cette liste.
Exemple : On souhaite définir un cluster qui consiste en deux machines A et B. Chacune des deux machines est maître et esclave de l’autre.
On doit définir non pas un mais deux clusters A et B :
Dans la définition du cluster A :
- Serveur courant : machine A (maître de ce cluster)
- machine B (esclave de ce cluster)
Dans la définition du cluster B :
- machine A (esclave de ce cluster)
- Serveur courant : machine B (maître de ce cluster)
On voit que dans le cluster B, le maître (B) n’est pas la première machine de la liste. Ce qui est important ici c’est que la liste machine A, machine B est bien la même sur les deux clusters (qu’elle que soit leur fonction propre au sein de leur cluster respectif).
Paramètres avancés spécifiques au clusters
Fichier modifié : system.xml
Exemple de syntaxe XML :
Paramètres disponibles :
- Nom : CUBE_UPLOAD_MODE
Valeur : entier : 0, 1 ou 2 (défaut : 1)
Description : Spécifie si les parts de cube doivent être téléchargées du serveur maître vers les serveurs esclaves au moment ou un utilisateur interagit avec le cube (1), quand le cube est généré par le serveur maître (2), ou jamais (0). Voir également le chapitre suivant : "Utiliser le cluster". - Nom : CLUSTER_TIMEOUT
Valeur : entier : (millisecondes, défaut: 30000)
Description : Spécifie le timeout de toutes les requêtes intra-cluster (entre le maître et les esclaves), à l’exception de la requête de vérification de disponibilité d’un esclave (voir ci-dessous) - Nom : CLUSTER_CHECK_TIMEOUT
Valeur : entier : (millisecondes, défaut: 5000)
Description : Spécifie le timeout de la requête de vérification de disponibilité d’un esclave. Ce timeout est plus court pour empêcher de bloquer trop longtemps le maître dans le cas ou un esclave est déconnecté du réseau.
Utiliser le cluster
Dans un déploiement simple en mode cluster il n'y a rien à faire de plus que ce qui a été écrit précédemment.
Malgré tout, il y a certains détails intéressants qui peuvent aider à améliorer la performance d'un cluster.
Le cluster est utilisé en fonction de la taille du cubes de données. En dessous d'un certain seuil, dépendant du cube, de la machine maître et des esclaves, il est possible que le cluster ne soit pas utilisé. Par contre si la taille d'un ou plusieurs cubes de données devient importante, par exemple au delà de plusieurs centaines de millions de lignes, ceux-ci seront découpés en plusieurs parties et leur calcul (aplatissement) sera réparti en parallèle sur tous les processeurs disponibles du cluster pour diminuer le temps de réponse global. Et ceci pour chaque aplatissement d'un gros cube par un utilisateur du tableau de bord, du mobile, etc.
Il est à noter que la génération des cubes est de la responsabilité du serveur maître. Les esclaves n'interviennent que lors des aplatissements interactifs de cubes déjà générés (ex: affichage d'un flux, filtrage, drill...)
Les morceaux de cubes sont envoyés aux esclaves à la demande (s'ils ne les ont pas déjà). Ceci peut induire un ralentissement du système sur un premier aplatissement demandé par un utilisateur, notamment si la bande passante du réseau est faible (< 1 gigabit).
Il y a toutefois différents moyens d'éviter cet encombrement du réseau. Voici quelques suggestions :
Un premier moyen est de disposer du dossier cubes (sous-dossier de Application Data/Enterprise Server/ddenterpriseapi par défaut) sur un disque réseau accessible à toutes les machines du cluster. Par exemple via un lien symbolique (Linux, NFS). Ce lien devra être établi pour toutes les machines du cluster. Le principe est que le serveur maître générera les cubes dans ce dossier réseau, et lors de l'interaction d'un utilisateur avec le système, maître et esclaves auront tous une vue commune des cubes. La lecture des cubes du disque n'étant faite qu'une fois dans le cycle de vie d'un cube (cube in-memory), l'impact du dossier réseau sur les performances est négligeable.
Un autre moyen, est d'utiliser un outil tierce de synchronisation automatique de dossiers entre plusieurs machines, qui pourra copier l'ensemble du dossier cubes du serveur, après leur génération, vers les machines esclaves. Le principe est que le serveur maître générera les cubes dans son dossier local, puis l'outil de synchronisation copiera ce dossier sur toutes les machines esclaves. Tout ceci en dehors des périodes d'activité du serveur. Maître et esclaves auront tous une vue identique des cubes.